# 并发容器
# 一、预备知识
# 1、Hash
把任意长度的输入(又叫做预映射, pre-image ),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。常用 Hash 函数:直接取余法、乘法取整法、平方取中法。
几种处理冲突的方法:
- 开放寻址法
- 再散列法
- 链地址法
# 2、位运算
# (1) 常用位运算
位与 & (1 & 1 = 1 , 0 & 0 = 0, 1 & 0 = 0)
位或 | (1 | 1 = 1, 0 | 0 = 0, 1 | 0 = 1)
位非 ~ (~1 = 0, ~0 = 1)
位异或 ^ (1 ^ 1 = 0, 1 ^ 0 = 1, 0 ^ 0 = 0)
有符号右移 >> (若正数,高位补0;负数,高位补1)
有符号左移 <<
无符号右移 >>> (不论正负,高位均补0)
取模 a % (2 ^ n) 等价于 a & (2 ^ n - 1),所以在 Map 里的数组个数一定是2的乘方数,计算 key 值在哪个元素中的时候,就用位运算来快速定位。
位运算的例子:
public class IntToBinary {
public static void main(String[] args) {
System.out.println("4 = " + Integer.toBinaryString(4));
System.out.println("6 = " + Integer.toBinaryString(6));
// 位与&(真真为真,真假为假,假假为假)
System.out.println("4 & 6 = " + Integer.toBinaryString(6 & 4));
// 位或|(真真为真,真假为真,假假为假)
System.out.println("4 | 6 = " + Integer.toBinaryString(6 | 4));
// 位非~
System.out.println("~4 = " + Integer.toBinaryString(~4));
// 位异或^(真真为假,真假为真,假假为假)
System.out.println("4 ^ 6 = " + Integer.toBinaryString(6 ^ 4));
// 有符号右移>>(若正数,高位补0;负数,高位补1)
System.out.println("4 >> 1 = " + Integer.toBinaryString(4 >> 1));
// 有符号左移<<(若正数,高位补0;负数,高位补1)
System.out.println("4 << 1 = " + Integer.toBinaryString(4 << 1));
// 无符号右移>>>(不论正负,高位均补0)
System.out.println("234567 = " + Integer.toBinaryString(234567));
System.out.println("234567 >>> 4 = " + Integer.toBinaryString(234567 >>> 4));
// 无符号右移>>>(不论正负,高位均补0)
System.out.println("-4 = " + Integer.toBinaryString(-4));
System.out.println("-4 >>> 4 = " + Integer.toBinaryString(-4 >>> 4));
System.out.println(Integer.parseInt(Integer.toBinaryString(-4 >>> 4), 2));
// 取模a % (2 ^ n) 等价于 a & (2 ^ n - 1)
System.out.println("345 % 16 = " + (345 % 16) + " or " + (345 & (16 - 1)));
// Hash值
System.out.println("Mark hashCode = " + "Mark".hashCode() + "="
+ Integer.toBinaryString("Mark".hashCode()));
System.out.println("Bill hashCode = " + "Bill".hashCode() + "="
+ Integer.toBinaryString("Bill".hashCode()));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
执行结果:
4 = 100
6 = 110
4 & 6 = 100
4 | 6 = 110
~4 = 11111111111111111111111111111011
4 ^ 6 = 10
4 >> 1 = 10
4 << 1 = 1000
234567 = 111001010001000111
234567 >>> 4 = 11100101000100
-4 = 11111111111111111111111111111100
-4 >>> 4 = 1111111111111111111111111111
268435455
345 % 16 = 9 or 9
Mark hashCode = 2390765=1001000111101011101101
Bill hashCode = 2070567=111111001100000100111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# (2) 位运算运用场景
Java中的类修饰符、成员变量修饰符、方法修饰符,比如Class类中Java容器中的HashMap和ConcurrentHashMap的实现- 权限控制或者商品属性
- 简单可逆加密,比如异或运算(
1 ^ 1 = 0,0 ^ 1 = 1)
权限控制的应用:
public class Permission {
/**
* 查询权限
*/
private static final int ALLOW_SELECT = 1 << 0;
/**
* 新增权限
*/
private static final int ALLOW_INSERT = 1 << 1;
/**
* 跟新权限
*/
private static final int ALLOW_UPDATE = 1 << 2;
/**
* 删除权限
*/
private static final int ALLOW_DELETE = 1 << 3;
/**
* 当前的权限状态
*/
private int flag;
public void setPermission(int permission) {
flag = permission;
}
/**
* 增加权限,可以一项或者多项
*
* @param permission
*/
public void addPermission(int permission) {
flag = flag | permission;
}
/**
* 删除权限,可以一项或者多项
*
* @param permission
*/
public void disablePermission(int permission) {
flag = flag & ~permission;
}
/**
* 是否拥有某些权限
*
* @param permission
* @return
*/
public boolean isAllow(int permission) {
return (flag & permission) == permission;
}
/**
* 是否不拥有某些权限
*
* @param permission
* @return
*/
public boolean isNotAllow(int permission) {
return (flag & permission) == 0;
}
public static void main(String[] args) {
int flag = 15;
Permission permission = new Permission();
permission.setPermission(flag);
permission.disablePermission(ALLOW_DELETE | ALLOW_INSERT);
System.out.println("ALLOW_SELECT = " + permission.isAllow(ALLOW_SELECT));
System.out.println("ALLOW_INSERT = " + permission.isAllow(ALLOW_INSERT));
System.out.println("ALLOW_UPDATE = " + permission.isAllow(ALLOW_UPDATE));
System.out.println("ALLOW_DELETE = " + permission.isAllow(ALLOW_DELETE));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
执行结果:
ALLOW_SELECT = true
ALLOW_INSERT = false
ALLOW_UPDATE = true
ALLOW_DELETE = false
2
3
4
# 二、为什么要使用 ConcurrentHashMap
# Java 1.7 中 HashMap 死循环分析
在多线程环境下,使用 HashMap 进行 put() 操作会引起死循环,导致 CPU 利用率接近 100%,HashMap 在并发执行 put() 操作时会引起死循环,是因为多线程会导致 HashMap 的 Entry 链表形成环形数据结构,一旦形成环形数据结构,Entry 的 next 节点永远不为空,就会产生死循环获取 Entry。
# (1) HashMap 扩容流程
HashMap 一次扩容的过程如下:
- 取当前
table的2倍作为新table的大小 - 根据算出的新
table的大小new出一个新的Entry数组来,名为newTable - 轮询原
table的每一个位置,将每个位置上连接的Entry,算出在新table上的位置,并以链表形式连接 - 原
table上的所有Entry全部轮询完毕之后,意味着原table上面的所有Entry已经移到了新的table上,HashMap中的table指向newTable
# (2) 并发下的扩容
HashMap 之所以在并发下的扩容造成死循环,是因为,多个线程并发进行时,因为一个线程先期完成了扩容,将原 Map 的链表重新散列到自己的表中,并且链表变成了倒序,后一个线程再扩容时,又进行自己的散列,再次将倒序链表变为正序链表。于是形成了一个环形链表,当 get() 表中不存在的元素时,造成死循环。
# 三、ConcurrentHashMap
# 1、使用
public class UseMap {
public static void main(String[] args) {
ConcurrentHashMap<KeyVo, String> map = new ConcurrentHashMap<>();
KeyVo keyVo = new KeyVo(1, "A");
System.out.println("put不存在的值:");
System.out.println(map.put(keyVo, "AA"));
System.out.println(map.get(keyVo));
System.out.println("put已存在的key:");
System.out.println(map.put(keyVo, "BB"));
System.out.println(map.get(keyVo));
System.out.println("putIfAbsent已存在的key:");
System.out.println(map.putIfAbsent(keyVo, "CC"));
System.out.println(map.get(keyVo));
System.out.println("putIfAbsent不存在的key:");
KeyVo keyVo2 = new KeyVo(2, "B");
System.out.println(map.putIfAbsent(keyVo2, "CC"));
System.out.println(map.get(keyVo2));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
用到的 KeyVo 类:
public class KeyVo {
private final int id;
private final String name;
public KeyVo(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyVo keyVo = (KeyVo) o;
return id == keyVo.id && Objects.equals(name, keyVo.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
执行结果:
put不存在的值:
null
AA
put已存在的key:
AA
BB
putIfAbsent已存在的key:
BB
BB
putIfAbsent不存在的key:
null
CC
2
3
4
5
6
7
8
9
10
11
12
putIfAbsent() 这个方法,如果传入 key 对应的 value 已经存在,就返回存在的 value,不进行替换。如果不存在,就添加 key 和 value,返回 null。在代码层面它的作用类似于:
synchronized(map){
if (map.get(key) == null){
return map.put(key, value);
} else{
return map.get(key);
}
}
2
3
4
5
6
7
它让整个操作是线程安全的。
# 2、ConcurrentHashMap 实现分析
# (1) 在 Java 1.7 下的实现
ConcurrentHashMap 在 Java 1.7 下的结构如下:

Segment 继承自 ReentrantLock,充当锁的角色:
static final class Segment<K, V> extends ReentrantLock
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构。一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得与它对应的 Segment 锁。
ConcurrentHashMap 的构造方法:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
ConcurrentHashMap 初始化方法是通过 initialCapacity、loadFactor 和 concurrencyLevel(参数 concurrencyLevel 是用户估计的并发级别,就是说你觉得最多有多少线程共同修改这个 map,根据这个来确定 Segment 数组的大小,concurrencyLevel 默认是 DEFAULT_CONCURRENCY_LEVEL = 16)等几个参数来初始化 Segment 数组、段偏移量 segmentShift、段掩码 segmentMask 和每个 Segment 里的 HashEntry 数组来实现的。
并发级别可以理解为程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的最大线程数,实际上就是 ConcurrentHashMap 中的分段锁个数,即 Segment[] 的数组长度。ConcurrentHashMap 默认的并发度为16,但用户也可以在构造函数中设置并发度。当用户设置并发度时,ConcurrentHashMap 会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)。
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个 Segment 内的访问会扩散到不同的 Segment 中,CPU cache 命中率会下降,从而引起程序性能下降。
Segment 数组的长度 ssize 是通过 concurrencyLevel 计算得出的。为了能通过按位与的散列算法来定位 Segment 数组的索引,必须保证 Segment 数组的长度是2的 N 次方,所以必须计算出一个大于或等于 concurrencyLevel 的最小的2的 N 次方值来作为 Segment 数组的长度。假如 concurrencyLevel 等于14、15或16,ssize 都会等于 16,即容器里锁的个数也是16。
输入参数 initialCapacity 是 ConcurrentHashMap 的初始化容量,loadfactor 是每个 Segment 的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个 Segment。上面代码中的变量 cap 就是 Segment 里 HashEntry 数组的长度,它等于 initialCapacity 除以 ssize 的倍数 c,如果 c 大于 1,就会取大于等于 c 的2的N 次方值,所以 Segment 里 HashEntry 数组的长度不是1,就是2的 N 次方。
在默认情况下, ssize = 16,initialCapacity = 16,loadFactor = 0.75f ,那么 cap = 1,threshold = (int) cap * loadFactor = 0。
既然 ConcurrentHashMap 使用分段锁 Segment 来保护不同段的数据,那么在插入和获取元素的时候,必须先通过散列算法定位到 Segment。
ConcurrentHashMap 会首先使用 Wang/Jenkins hash 的变种算法对元素的 hashCode 进行一次再散列。
ConcurrentHashMap 完全允许多个读操作并发进行,读操作并不需要加锁。ConcurrentHashMap 实现技术是保证 HashEntry 几乎是不可变的以及 volatile 关键字。
static final class HashEntry<K, V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K, V> next;
}
2
3
4
5
6
# get() 操作
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
第4行准备定位的 hash 值,第7行拿到 Segment 下的 table,第9行遍历 table 下指定的 HashEntry 链表。
get() 操作先经过一次再散列,然后使用这个散列值通过散列运算定位到 Segment (使用了散列值的高位部分),再通过散列算法定位到 table (使用了散列值的全部)。整个 get() 过程,没有加锁,而是通过 volatile 保证 get() 总是可以拿到最新值。
# put() 操作
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
2
3
4
5
6
7
8
9
10
11
第5行定位所需 hash 值,第9行初始化 segment[j] ,因为整个 map 初始化时,只初始化了 segment[0]。
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽,在插入第一个值的时候再进行初始化。
ensureSegment() 方法考虑了并发情况,多个线程同时进入初始化同一个槽 segment[k],但只要有一个成功就可以了。
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
其中的 while 循环使用 CAS 操作,保证了多线程下只有一个线程可以成功。
put() 方法中调用的 put(key, hash, value, false) 方法:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
通过 tryLock() 方法尝试获得锁,获得了锁,node 为 null 进入 try 语句块,没有获得锁,调用 scanAndLockForPut() 方法自旋等待获得锁:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
scanAndLockForPut() 方法里在尝试获得锁的过程中会对对应 hashcode 的链表进行遍历,如果遍历完毕仍然找不到与 key 相同的 HashEntry 节点,则为后续的 put() 操作提前创建一个 HashEntry。当 tryLock() 一定次数后仍无法获得锁,则通过 lock() 申请锁。
回到 put(K key, int hash, V value, boolean onlyIfAbsent) 方法:
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
2
3
4
5
6
7
8
9
10
11
12
13
在获得锁之后,Segment 对链表进行遍历,如果某个 HashEntry 节点具有相同的 key,则更新该 HashEntry 的 value 值,
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
否则新建一个 HashEntry 节点,采用头插法,将它设置为链表的新 head 节点并将原头节点设为新 head 的下一个节点。新建过程中如果节点总数(含新建的 HashEntry)超过 threshold,则调用 rehash() 方法对 Segment 进行扩容,最后将新建 HashEntry 写入到数组中。
# rehash() 操作
扩容是新创建了数组,然后进行迁移数据,最后再将 newTable 设置给属性 table。
为了避免让所有的节点都进行复制操作:由于扩容是基于2的幂指来操作,假设扩容前某 HashEntry 对应到 Segment 中数组的 index 为 i,数组的容量为 capacity,那么扩容后该 HashEntry 对应到新数组中的 index 只可能为 i 或者 i + capacity,因此很多 HashEntry 节点在扩容前后 index 可以保持不变。
该方法没有考虑并发,因为执行该方法之前已经获取了锁。
# remove() 操作
与 put() 方法类似,都是在操作前需要拿到锁,以保证操作的线程安全性。
# size() containsValue() 操作
这些方法都是基于整个 ConcurrentHashMap 来进行操作的,他们的原理也基本类似。以 size() 方法为例,首先不加锁循环执行以下操作:循环所有的 Segment,获得对应的值以及所有 Segment 的 modcount 之和。在 put() 、 remove() 和 clean() 方法里操作元素前都会将变量 modCount 进行变动,如果连续两次所有 Segment 的 modcount 和相等,则过程中没有发生其他线程修改 ConcurrentHashMap 的情况,返回获得的值。
当循环次数超过预定义的值时,这时需要对所有的 Segment 依次进行加锁,获取返回值后再依次解锁。所以一般来说,应该避免在多线程环境下使用 size() 和 containsValue() 方法。
# ConcurrentHashMap 的弱一致性
由于遍历过程中其他线程可能对链表结构做了调整,因此 get() 和 containsKey() 返回的可能是过时的数据,这一点是 ConcurrentHashMap 在弱一致性上的体现。如果要求强一致性,那么必须使用 Collections.synchronizedMap() 方法。
# (2) 在 Java 1.8 下的实现

# 改进
取消
Segment<K,V>[] segments字段,直接采用transient volatile HashEntry<K, V>[] table保存数据,采用table数组元素作为锁,从而实现了对缩小锁的粒度,进一步减少并发冲突的概率,并大量使用了采用了CAS+synchronized来保证并发安全性。将原先
table数组 + 单向链表的数据结构,变更为table数组 + 单向链表 + 红黑树的结构。对于hash表来说,最核心的能力在于将keyhash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为 0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk 1.8 中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
使用 Node(jdk 1.7 为 Entry) 作为链表的数据结点,仍然包含 key,value,hash 和 next 四个属性。 红黑树的情况使用的是 TreeNode extends Node。根据数组元素中,第一个结点数据类型是 Node 还是 TreeNode 可以判断该位置下是链表还是红黑树。
用于判断是否需要将链表转换为红黑树的阈值:
static final int TREEIFY_THRESHOLD = 8;
用于判断是否需要将红黑树转换为链表的阈值:
static final int UNTREEIFY_THRESHOLD = 6;
# 核心数据结构和属性
# Node
Node 是最核心的内部类,它包装了 key-value 键值对:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
定义基本和 jdk 1.7 中的 HashEntry 相同。整个 ConcurrentHashMap 本身所持有的也是一个 Node 型的数组:
transient volatile Node<K,V>[] table;
增加了一个 find() 方法来用以辅助 get() 方法。其实就是遍历链表,子类中会覆盖这个方法。
# TreeNode
树节点类,另外一个核心的数据结构。当链表长度过长的时候,会转换为 TreeNode:
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
*/
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
它与 jdk 1.8 中 HashMap 不同点:
它并不是直接转换为红黑树,而是把这些结点放在
TreeBin对象中,由TreeBin完成对红黑树的包装。TreeNode在ConcurrentHashMap扩展自Node类,而并非HashMap中的扩展自LinkedHashMap.Entry<K,V>类,也就是说TreeNode带有next指针。
# TreeBin
负责 TreeNode 节点。它代替了 TreeNode 的根节点,也就是说在实际的 ConcurrentHashMap “数组”中,存放的是 TreeBin 对象,而不是 TreeNode 对象。另外这个类还带有了读写锁机制。
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
...
2
3
4
5
6
7
8
9
10
# ForwardingNode
一个特殊的 Node 结点,hash 值为-1,其中存储 nextTable 的引用。有 table 发生扩容的时候,ForwardingNode 发挥作用,作为一个占位符放在 table 中表示当前结点为 null或者已经被移动。
# sizeCtl
用来控制 table 的初始化和扩容操作。
负数代表正在进行初始化或扩容操作:
- -1:代表正在初始化
- -N:表示有
N-1个线程正在进行扩容操作 - 0:为默认值,代表当时的
table还没有被初始化 - 正数表示初始化大小或
ConcurrentHashMap中的元素达到这个数量时,需要进行扩容了。
# 几个核心方法
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
2
3
4
5
6
7
8
9
10
11
12
tabAt():利用硬件级别的原子操作,获得在 i 位置上的 Node 节点,U.getObjectVolatile() 可以直接获取指定内存的数据,保证了每次拿到数据都是最新的。
casTabAt():利用 CAS 操作设置 i 位置上的 Node 节点
setTabAt():利用硬件级别的原子操作,获得在 i 位置上的 Node 节点,U.putObjectVolatile() 可以直接设定指定内存的数据,保证了其他线程访问这个节点时一定可以看到最新的数据。
# 构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
2
3
4
5
6
7
8
9
10
11
可以发现,在 new 出一个 ConcurrentHashMap 的实例时,并不会创建其中的数组等等相关的部件,只是进行简单的属性设置而已,同样的,table 的大小也被规定为必须是2的乘方数。
真正的初始化在放在了是在向 ConcurrentHashMap 中插入元素的时候发生的。如调用 put()、computeIfAbsent()、compute()、merge() 等方法的时候,调用时机是检查 table == null。
# get() 操作
get() 方法比较简单,给定一个 key 来确定 value 的时候,必须满足两个条件: key 相同 hash 值相同,对于节点可能在链表或树上的情况,需要分别去查找。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 计算hash值
int h = spread(key.hashCode());
// 根据hash值确定节点位置
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// Node数组中的节点就是要找的节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// eh<0 说明这个节点在树上 调用树的find方法寻找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 到这一步说明是个链表,遍历链表找到对应的值并返回
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# put() 操作
public V put(K key, V value) {
return putVal(key, value, false);
}
2
3
put() 方法又调用了 putVal() 方法:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
// 死循环 何时插入成功 何时跳出
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 如果table为空的话,初始化table
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// Node数组中的元素,这个位置没有值 ,使用CAS操作放进去
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
// 正在进行扩容,当前线程帮忙扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 锁Node数组中的元素,这个位置是Hash冲突组成链表的头结点或者是红黑树的根节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// fh>0 说明这个节点是一个链表的节点 不是树的节点
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// put操作和putIfAbsent操作业务实现
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 如果遍历到了最后一个结点,使用尾插法,把它插入在链表尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 按照树的方式插入值
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 达到临界值8 就需要把链表转换为树结构
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// Map的元素数量+1,并检查是否需要扩容
addCount(1L, binCount);
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
总结来说,put() 方法就是,沿用 HashMap 的 put() 方法的思想,根据 hash 值计算这个新插入的点在 table 中的位置 i,如果 i 位置是空的,直接放进去,否则进行判断,如果 i 位置是树节点,按照树的方式插入新的节点,否则把 i 插入到链表的末尾。
整体流程上,就是首先定义不允许 key 或 value 为 null 的情况放入,对于每一个放入的值,首先利用 spread() 方法对 key 的 hashcode 进行一次 hash 计算,由此来确定这个值在 table 中的位置。
如果这个位置是空的,那么直接放入,而且不需要加锁操作。
如果这个位置存在结点,说明发生了 hash 碰撞,首先判断这个节点的类型。如果是链表节点,则得到的结点就是 hash 值相同的节点组成的链表的头节点。需要依次向后遍历确定这个新加入的值所在位置。如果遇到 hash 值与 key 值都与新加入节点是一致的情况,则只需要更新 value 值即可。否则依次向后遍历,直到链表尾插入这个结点。如果加入这个节点以后链表长度大于 8,就把这个链表转换成红黑树。如果这个节点的类型已经是树节点的话,直接调用树节点的插入方法进行插入新的值。
# initTable() 方法
构造方法中并没有真正初始化,真正的初始化在放在了是在向 ConcurrentHashMap 中插入元素的时候发生的。具体实现的方法就是 initTable():
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 小于0表示有其他线程正在进行初始化操作,把当前线程CPU时间让出来。因为对于table的初始化工作,只能有一个线程在进行。
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 利用CAS操作把sizectl的值置为-1 表示本线程正在进行初始化
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// n右移2位本质上就是n变为n原值的1/4,所以sc=0.75*n
sc = n - (n >>> 2);
}
} finally {
// 将设置成扩容的阈值
sizeCtl = sc;
}
break;
}
}
return tab;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# transfer() 方法
当 ConcurrentHashMap 容量不足的时候,需要对 table 进行扩容。这个方法的基本思想跟 HashMap 是很像的,但是由于它是支持并发扩容的,所以要复杂的多。下面讲讲大概原理。
为何要并发扩容?因为在扩容的时候,总是会涉及到从一个“数组”到另一个“数组”拷贝的操作,如果这个操作能够并发进行,就能利用并发处理去减少扩容带来的时间影响。
整个扩容操作分为两个部分:
第一部分是构建一个 nextTable ,它的容量是原来的2倍。
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
2
3
4
5
第二个部分就是将原来 table 中的元素复制到 nextTable 中,这里允许多线程进行操作。整个扩容流程就是遍历和复制。
为 null 或者已经处理过的节点,会被设置为 forwardNode 节点,当线程准备扩容时,发现节点是 forwardNode 节点,跳过这个节点,继续寻找未处理的节点,找到了,对节点上锁。
如果这个位置是 Node 节点(fh >= 0),说明它是一个链表,就构造一个反序链表,把他们分别放在 nextTable 的 i 和 i + n 的位置上。
如果这个位置是 TreeBin 节点(fh < 0),也做一个反序处理,并且判断是否需要红黑树转链表,把处理的结果分别放在 nextTable 的 i 和 i + n 的位置上
遍历过所有的节点以后就完成了复制工作,这时让 nextTable 作为新的 table,并且更新 sizeCtl 为新容量的 0.75 倍 ,完成扩容。
并发扩容其实就是将数据迁移任务拆分成多个小迁移任务,在实现上使用了一个变量 stride 作为步长控制,每个线程每次负责迁移其中的一部分。
# remove() 方法
用于将过长的链表转换为 TreeBin 对象。但是他并不是直接转换,而是进行一次容量判断,如果容量没有达到转换的要求,直接进行扩容操作并返回;如果满足条件才将链表的结构转换为 TreeBin ,这与 HashMap 不同的是,它并没有把 TreeNode 直接放入红黑树,而是利用了 TreeBin 这个小容器来封装所有的 TreeNode。
# size() 方法
在 jdk 1.8 版本中,对于 size() 的计算,在扩容和 addCount() 方法就已经有处理了,可以注意一下 put() 函数,里面就有 addCount() 函数,早就计算好的,然后 size() 的时候直接返回。jdk 1.7 是在调用 size() 方法才去计算,其实在并发集合中去计算 size() 是没有多大的意义的,因为 size() 是实时在变的。
addCount() 方法:
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
在具体实现上,计算大小的核心方法都是 sumCount():
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
2
3
4
5
6
7
8
9
10
11
可以看见,统计数量时使用了 baseCount 、和 CounterCell 类型的变量 counterCells 。其实 baseCount 就是记录容器数量的,而 counterCells 则是记录 CAS 更新 baseCounter 值时,由于高并发而导致失败的值。这两个变量的变化在 addCount() 方法中有体现,大致的流程就是:
- 对
baseCount做CAS自增操作。 - 如果并发导致
baseCount的CAS失败了,则使用counterCells。 - 如果
counterCells的CAS失败了,在fullAddCount()方法中,会继续死循环操作,直到成功。
# 3、HashTable
HashTable 容器使用 synchronized 来保证线程安全,但在线程竞争激烈的情况下 HashTable 的效率非常低下。因为当一个线程访问 HashTable 的同步方法,其他线程也访问 HashTable 的同步方法时,会进入阻塞或轮询状态。如线程1使用 put() 进行元素添加,线程2不但不能使用 put() 方法添加元素,也不能使用 get() 方法来获取元素,所以竞争越激烈效率越低。
# 4、并发下的 Map 常见面试题
# (1) HashMap 和 HashTable 有什么区别
HashMap是线程不安全的,HashTable是线程安全的;- 由于线程安全,所以
HashTable的效率比不上HashMap; HashMap最多只允许一条记录的键为null,允许多条记录的值为null,而HashTable不允许;HashMap默认初始化数组的大小为16,HashTable为11,前者扩容时,扩大两倍,后者扩大两倍+1;HashMap需要重新计算hash值,而HashTable直接使用对象的hashCode
# (2) Java 中的另一个线程安全的与 HashMap 极其类似的类是什么?同样是线程安全,它与 HashTable 在线程同步上有什么不同?
ConcurrentHashMap 类(是 Java 并发包 java.util.concurrent中提供的一个线程安全且高效的 HashMap 实现)。
HashTable 是使用 synchronize 关键字加锁的原理(就是对对象加锁);而针对 ConcurrentHashMap,在 JDK 1.7中采用分段锁的方式;JDK 1.8 中直接采用了 CAS(无锁算法)+ synchronized,也采用分段锁的方式并大大缩小了锁的粒度。
# (3) HashMap 和 ConcurrentHashMap 的区别?
除了加锁,原理上无太大区别。
另外,HashMap 的键值对允许有 null,但是 ConCurrentHashMap 都不允许。
在数据结构上,红黑树相关的节点类不同。HashMap 的节点类是继承 LinkedHashMap.Entry ConcurrentHashMap 的节点类是内部单独定义的 Node。
# (4) 为什么 ConcurrentHashMap 比 HashTable 效率要高?
HashTable 使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
ConcurrentHashMap 在 jdk 1.7 中使用分段锁(ReentrantLock + Segment + HashEntry),相当于把一个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于 Segment,一个 Segment 包含多个 HashEntry。
在 jdk 1.8 中使用 CAS + synchronized + Node + 红黑树。锁粒度:Node(首结点)(实现 Map.Entry<K,V>)。锁粒度降低了。
# (5) 针对 ConcurrentHashMap 锁机制具体分析(jdk 1.7 VS jdk 1.8)?
jdk 1.7 中,采用分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构,包括两个核心静态内部类 Segment 和 HashEntry。
Segment继承ReentrantLock(重入锁) 用来充当锁的角色,每个Segment对象守护每个散列映射表的若干个桶HashEntry用来封装映射表的键-值对- 每个桶是由若干个
HashEntry对象链接起来的链表
jdk 1.8 中,采用 Node + CAS + Synchronized 来保证并发安全。取消类 Segment,直接用 table 数组存储键值对;当 HashEntry 对象组成的链表长度超过 TREEIFY_THRESHOLD 时,链表转换为红黑树,提升性能。底层变更为数组 + 链表 + 红黑树。
# (6) ConcurrentHashMap 在 JDK 1.8 中,为什么要使用内置锁 synchronized 来代替重入锁 ReentrantLock?
JVM开发团队在jdk 1.8中对synchronized做了大量性能上的优化,而且基于JVM的synchronized优化空间更大,更加自然。- 在大量的数据操作下,对于
JVM的内存压力,基于API的ReentrantLock会开销更多的内存。
# (7) ConcurrentHashMap 简单介绍
- 重要的常量:
private transient volatile int sizeCtl;
- 当为负数时,-1 表示正在初始化,
-N表示N - 1个线程正在进行扩容; - 当为 0 时,表示
table还没有初始化; - 当为其他正数时,表示初始化或者下一次进行扩容的大小。
- 数据结构:
Node 是存储结构的基本单元,继承 HashMap 中的 Entry,用于存储数据;
TreeNode 继承 Node,但是数据结构换成了二叉树结构,是红黑树的存储结构,用于红黑树中存储数据;
TreeBin 是封装 TreeNode 的容器,提供转换红黑树的一些条件和锁的控制。
- 存储对象时(
put()方法):
- 如果没有初始化,就调用
initTable()方法来进行初始化; - 如果没有
hash冲突就直接CAS无锁插入; - 如果需要扩容,就先进行扩容;
- 如果存在
hash冲突,就加锁来保证线程安全,两种情况:一种是链表形 式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入; - 如果该链表的数量大于阀值8,就要先转换成红黑树的结构,
break再一 次进入循环 - 如果添加成功就调用
addCount()方法统计size(),并且检查是否需要扩容。
扩容方法
transfer():默认容量为16,扩容时,容量变为原来的两倍。helpTransfer():调用多个工作线程一起帮助进行扩容,这样的效率就会更高。获取对象时(
get()方法):
- 计算
hash值,定位到该table索引位置,如果是首结点符合就返回; - 如果遇到扩容时,会调用标记正在扩容结点
ForwardingNode.find()方法,查找该结点,匹配就返回; - 以上都不符合的话,就往下遍历结点,匹配就返回,否则最后就返回
null。
# (8) ConcurrentHashMap 的并发度是什么
jdk 1.7 中程序运行时能够同时更新 ConccurentHashMap 且不产生锁竞争的最大线程数。默认为16,且可以在构造函数中设置。当用户设置并发度时,ConcurrentHashMap 会使用大于等于该值的最小2 幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为 32)。
jdk 1.8 中并发度则无太大的实际意义了,主要用处就是当设置的初始容量小于并发度,将初始容量提升至并发度大小。
# 四、ConcurrentSkipList 系列
ConcurrentSkipListMap 是个有序 Map,ConcurrentSkipListSet 是个有序 Set。
TreeMap 和 TreeSet 使用红黑树按照 key 的顺序(自然顺序、自定义顺序)来使得键值对有序存储,但是只能在单线程下安全使用;多线程下想要使键值对按照 key 的顺序来存储,则需要使用 ConcurrentSkipListMap 和 ConcurrentSkipListSet,分别用以代替 TreeMap 和 TreeSet,存入的数据按 key 排序。在实现上,ConcurrentSkipListSet 本质上就是 ConcurrentSkipListMap。
# 1、了解什么是 SkipList
# (1) 二分查找和 AVL 树查找
二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存。这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了。
如果需要的是一个能够进行二分查找,又能快速添加和删除元素的数据结构,首先就是二叉查找树,二叉查找树在最坏情况下可能变成一个链表。
于是,就出现了平衡二叉树,根据平衡算法的不同有 AVL 树,B-Tree,B+Tree,红黑树等,但是 AVL 树实现起来比较复杂,平衡操作较难理解,这时候就可以用 SkipList 跳跃表结构。
# (2) 什么是跳表
传统意义的单链表是一个线性结构,向有序的链表中插入一个节点需要 O(n) 的时间,查找操作需要 O(n) 的时间。
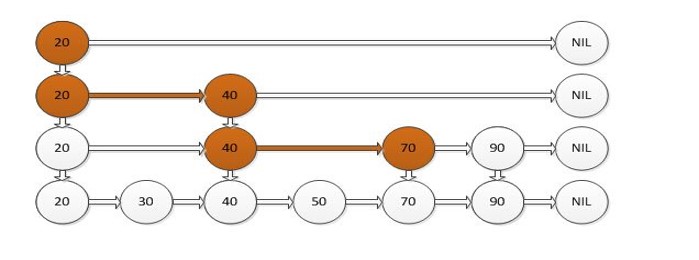
如果我们使用上图所示的跳跃表,就可以减少查找所需时间为 O(n/2),因为我们可以先通过每个节点的最上面的指针先进行查找,这样子就能跳过一半的节点。
比如我们想查找50,首先和20比较,大于20之后,再和40进行比较,然后再和70进行比较,发现70大于50,说明查找的点在40和50之间,从这个过程中,我们可以看出,查找的时候跳过了30。
跳跃表其实也是一种通过“空间来换取时间”的一个算法,令链表的每个结点不仅记录 next 结点位置,还可以按照 level 层级分别记录后继第 level 个结点。此法使用的就是“先大步查找确定范围,再逐渐缩小迫近”的思想进行的查找。跳跃表在算法效率上很接近红黑树。
跳跃表又被称为概率,或者说是随机化的数据结构,目前开源软件 Redis 和 lucence 都有用到它。
ConcurrentHashMap 和 ConcurrentSkipListMap 都是线程安全的 Map 实现,ConcurrentHashMap 的性能和存储空间要优于 ConcurrentSkipListMap ,但是 ConcurrentSkipListMap 有一个功能: 它会按照键的顺序进行排序。
# 2、ConcurrentLinkedQueue
无界非阻塞队列,它是一个基于链表的无界线程安全队列。该队列的元素遵循先进先出的原则。头是最先加入的,尾是最近加入的。插入元素是追加到尾上。提取一个元素是从头提取。可以看成是 LinkedList 的并发版本,常用方法:
concurrentLinkedQueue.add("c")
concurrentLinkedQueue.offer("d")
将指定元素插入到此队列的尾部。
- concurrentLinkedQueue.peek();
检索并不移除此队列的头,如果此队列为空,则返回 null。
- concurrentLinkedQueue.poll();
检索并移除此队列的头,如果此队列为空,则返回 null。
# 3、写时复制容器
# (1) 什么是写时复制容器
写时复制容器有 CopyOnWriteArrayList 、 CopyOnWriteArraySet 以及 CopyOnWriteMap。
CopyOnWrite 容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器。如果读的时候有多个线程正在向 CopyOnWrite 容器中添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的CopyOnWrite 容器。
CopyOnWrite 并发容器用于对于绝大部分访问都是读,且只是偶尔写的并发场景。比如白名单,黑名单,商品类目的访问和更新场景,假如我们有一个搜索网站,用户在这个网站的搜索框中,输入关键字搜索内容,但是某些关键字不允许被搜索。这些不能被搜索的关键字会被放在一个黑名单当中,黑名单每天晚上更新一次。当用户搜索时,会检查当前关键字在不在黑名单当中,如果在,则提示不能搜索。
在使用 CopyOnWriteMap 需要注意两件事情:
- 减少扩容开销。根据实际需要,初始化
CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。 - 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。
# (2) 写时复制容器的问题
# 性能问题
每次修改都创建一个新数组,然后复制所有内容,如果数组比较大,修改操作又比较频繁,可以想象,性能是很低的,而且内存开销会很大。
# 数据一致性问题
CopyOnWrite 容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,不要使用 CopyOnWrite 容器。
# 4、阻塞队列 BlockingQueue
# (1) 什么是阻塞队列
- 支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。
- 支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序整体处理数据的速度。
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。
为了解决这种生产消费能力不均衡的问题,便有了生产者和消费者模式。生产者和消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。
| 方法 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入方法 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除方法 | remove() | poll() | take() | poll(time, unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
抛出异常:当队列满时,如果再往队列里插入元素,会抛出
IllegalStateException("Queuefull")异常。当队列空时,从队列里获取元素会抛出NoSuchElementException异常。返回特殊值:当往队列插入元素时,会返回元素是否插入成功,成功返回
true。如果是移除方法,则是从队列里取出一个元素,如果没有则返回null。一直阻塞:当阻塞队列满时,如果生产者线程往队列里
put()元素,队列会一直阻塞生产者线程,直到队列可用或者响应中断退出。当队列空时,如果消费者线程从队列里take()元素,队列会阻塞住消费者线程,直到队列不为空。超时退出:当阻塞队列满时,如果生产者线程往队列里插入元素,队列会阻塞生产者线程一段时间,如果超过了指定的时间,生产者线程就会退出。
# (2) 常用阻塞队列
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
# 有界和无界
有限队列就是长度有限,满了以后生产者会阻塞,无界队列就是里面能放无数的东西而不会因为队列长度限制被阻塞,当然空间限制来源于系统资源的限制,如果处理不及时,导致队列越来越大越来越大,超出一定的限制致使内存超限,操作系统或者 JVM 帮你解决烦恼,直接把你 OOM kill 省事了。
# ArrayBlockingQueue
是一个用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证线程公平的访问队列,所谓公平访问队列是指阻塞的线程,可以按照阻塞的先后顺序访问队列,即先阻塞线程先访问队列。非公平性是对先等待的线程是非公平的,当队列可用时,阻塞的线程都可以争夺访问队列的资格,有可能先阻塞的线程最后才访问队列。初始化时有参数可以设置
# LinkedBlockingQueue
是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为 Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
# Array 实现和 Linked 实现的区别
- 队列中锁的实现不同
ArrayBlockingQueue 实现的队列中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue 实现的队列中的锁是分离的,即生产用的是 putLock,消费是 takeLock
- 在生产或消费时操作不同
ArrayBlockingQueue 实现的队列中在生产和消费的时候,是直接将枚举对象插入或移除的;
LinkedBlockingQueue 实现的队列中在生产和消费的时候,需要把枚举对象转换为 Node<E> 进行插入或移除,会影响性能
- 队列大小初始化方式不同
ArrayBlockingQueue 实现的队列中必须指定队列的大小;
LinkedBlockingQueue 实现的队列中可以不指定队列的大小,但是默认是 Integer.MAX_VALUE
# PriorityBlockingQueue
PriorityBlockingQueue 是一个支持优先级的无界阻塞队列。默认情况下元素采取自然顺序升序排列。也可以自定义类实现 compareTo() 方法来指定元素排序规则,或者初始化 PriorityBlockingQueue 时,指定构造参数 Comparator 来对元素进行排序。需要注意的是不能保证同优先级元素的顺序。
# DelayQueue
是一个支持延时获取元素的无界阻塞队列。队列使用 PriorityQueue 来实现。队列中的元素必须实现 Delayed 接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
DelayQueue 非常有用,可以将 DelayQueue 运用在以下应用场景:
缓存系统的设计。可以用
DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。订单到期,限时支付等等
下面演示 DelayQueue 的使用例子。
订单类:
public class Order {
/**
* 订单编号
*/
private final String orderNo;
/**
* 订单金额
*/
private final double orderMoney;
public Order(String orderNo, double orderMoney) {
this.orderNo = orderNo;
this.orderMoney = orderMoney;
}
public String getOrderNo() {
return orderNo;
}
public double getOrderMoney() {
return orderMoney;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
实际需要放入延迟队列的元素:
public class ItemVo<T> implements Delayed {
/**
* 到期时间,但传入的数值代表过期的时长,传入单位毫秒
*/
private long activeTime;
/**
* 业务数据
*/
private T data;
/**
* 传入过期时长,内部转换
*
* @param expirationTime 单位秒
* @param data
*/
public ItemVo(long expirationTime, T data) {
this.activeTime = expirationTime * 1000 + System.currentTimeMillis();
this.data = data;
}
public long getActiveTime() {
return activeTime;
}
public T getData() {
return data;
}
/**
* 这个方法返回到激活日期的剩余时间,时间单位由单位参数指定。
*
* @param unit
* @return
*/
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(activeTime - System.currentTimeMillis(), unit);
}
/**
* Delayed接口继承了Comparable接口,按剩余时间排序,实际计算考虑精度为纳秒数
*
* @param o
* @return
*/
@Override
public int compareTo(Delayed o) {
long d = (getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS));
if (d == 0) {
return 0;
} else {
if (d < 0) {
return -1;
} else {
return 1;
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
实现了 Delayed 接口表示:只有在延迟期满时才能从队列中提取元素。
需要取出到期订单的类:
public class FetchOrder implements Runnable {
private DelayQueue<ItemVo<Order>> queue;
public FetchOrder(DelayQueue<ItemVo<Order>> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
ItemVo<Order> item = queue.take();
Order order = item.getData();
System.out.println("get from queue, " + "data: " + order.getOrderNo() + ", " + order.getOrderMoney());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
将订单放入延迟队列的类:
public class PutOrder implements Runnable {
private DelayQueue<ItemVo<Order>> queue;
public PutOrder(DelayQueue<ItemVo<Order>> queue) {
this.queue = queue;
}
@Override
public void run() {
// 5秒后到期
Order orderTb = new Order("Tb12345", 366);
ItemVo<Order> itemTb = new ItemVo<>(5, orderTb);
queue.offer(itemTb);
System.out.println("订单5秒后超时:" + orderTb.getOrderNo() + "," + orderTb.getOrderMoney());
// 8秒后到期
Order orderJd = new Order("Jd54321", 366);
ItemVo<Order> itemJd = new ItemVo<>(8, orderJd);
queue.offer(itemJd);
System.out.println("订单8秒后超时:" + orderJd.getOrderNo() + "," + orderJd.getOrderMoney());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
测试类:
public class Test {
public static void main(String[] args) throws InterruptedException {
DelayQueue<ItemVo<Order>> queue = new DelayQueue<ItemVo<Order>>();
new Thread(new PutOrder(queue)).start();
new Thread(new FetchOrder(queue)).start();
// 每隔500毫秒,打印个数字
for (int i = 1; i < 15; i++) {
Thread.sleep(1000);
System.out.println(i * 1000);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
执行结果:
订单5秒后超时:Tb12345,366.0
订单8秒后超时:Jd54321,366.0
1000
2000
3000
4000
get from queue, data: Tb12345, 366.0
5000
6000
7000
get from queue, data: Jd54321, 366.0
8000
9000
10000
11000
12000
13000
14000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# SynchronousQueue
是一个不存储元素的阻塞队列。每一个 put() 操作必须等待一个 take() 操作,否则不能继续添加元素。SynchronousQueue 可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合传递性场景。SynchronousQueue 的吞吐量高于 LinkedBlockingQueue 和 ArrayBlockingQueue。
# LinkedTransferQueue
tryTransfer() 和 transfer() 方法:
transfer()方法
如果当前有消费者正在等待接收元素(消费者使用 take() 方法或带时间限制的 poll() 方法时),transfer() 方法可以把生产者传入的元素立刻 传输给消费者。如果没有消费者在等待接收元素,transfer() 方法会将元素存放在队列的 tail 节点,并等到该元素被消费者消费了才返回。
tryTransfer()方法tryTransfer()方法是用来试探生产者传入的元素是否能直接传给消费者。如果没有消费者等待接收元素,则返回false。和transfer()方法的区别是tryTransfer()方法无论消费者是否接收,方法立即返回,而transfer()方法是必须等到消费者消费了才返回。
# LinkedBlockingDeque
LinkedBlockingDeque 是一个由链表结构组成的双向阻塞队列。所谓双向队列指的是可以从队列的两端插入和移出元素。双向队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。
多了 addFirst() 、addLast() 、offerFirst() 、offerLast() 、peekFirst() 和 peekLast() 等方法,以 First 单词结尾的方法,表示插入、获取(peek)或移除双端队列的第一个元素。以 Last 单词结尾的方法,表示插入、获取或移除双端队列的最后一个元素。另外,插入方法 add() 等同于 addLast(),移除方法 remove() 等效于 removeFirst()。但是 take() 方法却等同于 takeFirst(),不知道是不是 jdk 的 bug,使用时还是用带有 First 和 Last 后缀的方法更清楚。在初始化 LinkedBlockingDeque 时可以设置容量防止其过度膨胀。另外,双向阻塞队列可以运用在“工作窃取”模式中。
# (3) 了解阻塞队列的实现原理
使用了等待通知模式实现。所谓通知模式,就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。通过查看 jdk 源码发现 ArrayBlockingQueue 使用了 Condition 来实现。
# (4) 几种阻塞队列的实现
首先定义一个接口,有两个方法,一个放入元素的方法,一个取出元素的方法:
public interface IBoundedBuffer<E> {
void put(E e) throws InterruptedException;
E take() throws InterruptedException;
}
2
3
4
5
6
# wait()、notify() 实现
public class WaitNotifyImpl<E> implements IBoundedBuffer<E> {
private List<E> queue = new LinkedList<>();
private final int limit;
public WaitNotifyImpl(int limit) {
this.limit = limit;
}
@Override
public synchronized void put(E e) throws InterruptedException {
while (queue.size() == limit) {
wait();
}
queue.add(e);
notifyAll();
}
@Override
public synchronized E take() throws InterruptedException {
while (queue.size() == 0) {
wait();
}
E e = queue.remove(0);
notifyAll();
return e;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Lock、Condition 的实现
public class LockConditionImpl<E> implements IBoundedBuffer<E> {
private List<E> queue = new LinkedList<>();
private final int limit;
private final Lock lock = new ReentrantLock();
private final Condition notFull = lock.newCondition();
private final Condition notEmpty = lock.newCondition();
public LockConditionImpl(int limit) {
this.limit = limit;
}
@Override
public void put(E e) throws InterruptedException {
lock.lock();
try {
while (queue.size() == limit) {
notFull.await();
}
queue.add(e);
notEmpty.signal();
} finally {
lock.unlock();
}
}
@Override
public E take() throws InterruptedException {
lock.lock();
try {
while (queue.size() == 0) {
notEmpty.await();
}
E e = queue.remove(0);
notFull.signal();
return e;
} finally {
lock.unlock();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# Semaphore 的实现
public class SemaphoreImpl<E> implements IBoundedBuffer<E> {
private List<E> queue = new LinkedList<>();
private final Semaphore space;
private final Semaphore item;
public SemaphoreImpl(int limit) {
space = new Semaphore(limit);
item = new Semaphore(0);
}
@Override
public void put(E e) throws InterruptedException {
space.acquire();
synchronized (this) {
queue.add(e);
}
item.release();
}
@Override
public E take() throws InterruptedException {
E e;
item.acquire();
synchronized (this) {
e = (E) queue.remove(0);
}
space.release();
return e;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Loop 实现
public class LoopSleepImpl<E> implements IBoundedBuffer<E> {
private List<E> queue = new LinkedList<>();
private final int limit;
private final static int INTERVAL = 50;
public LoopSleepImpl(int limit) {
this.limit = limit;
}
@Override
public void put(E e) throws InterruptedException {
while (true) {
synchronized (this) {
if (!(queue.size() == limit)) {
queue.add(e);
return;
}
}
Thread.sleep(INTERVAL);
}
}
@Override
public E take() throws InterruptedException {
while (true) {
synchronized (this) {
if (!(queue.size() == 0)) {
return (E) queue.remove(0);
}
}
Thread.sleep(INTERVAL);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 测试
public class Test {
private static class PutThread implements Runnable {
private IBoundedBuffer<String> boundedBuffer;
public PutThread(IBoundedBuffer<String> boundedBuffer) {
this.boundedBuffer = boundedBuffer;
}
@Override
public void run() {
System.out.println("PutThread is running ...");
Random random = new Random();
for (int i = 0; i < 20; i++) {
int number = random.nextInt();
try {
boundedBuffer.put("count[" + i + "] = " + number);
System.out.println("PutThread put: count[" + i + "] = " + number);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
private static class TakeThread implements Runnable {
private String name;
private IBoundedBuffer<String> boundedBuffer;
public TakeThread(IBoundedBuffer<String> boundedBuffer, String name) {
this.boundedBuffer = boundedBuffer;
this.name = name;
}
@Override
public void run() {
Thread.currentThread().setName(name);
System.out.println(name + " is running ...");
Random random = new Random();
while (!Thread.currentThread().isInterrupted()) {
try {
String msg = boundedBuffer.take();
System.out.println(name + " get " + msg);
Thread.sleep(random.nextInt(2000) + 500);
} catch (InterruptedException e) {
System.out.println(name + "被中断!");
break;
}
}
}
}
public static void main(String[] args) throws InterruptedException {
IBoundedBuffer<String> boundedBuffer = new WaitNotifyImpl<>(10);
Thread put1 = new Thread(new PutThread(boundedBuffer));
Thread take1 = new Thread(new TakeThread(boundedBuffer, "TakeThread1"));
Thread take2 = new Thread(new TakeThread(boundedBuffer, "TakeThread2"));
put1.start();
Thread.sleep(2000);
take1.start();
take2.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
使用不同的实现类进行测试即可,执行结果:
PutThread is running ...
PutThread put: count[0] = 1868845248
PutThread put: count[1] = -632455211
PutThread put: count[2] = 1793924123
PutThread put: count[3] = 721589803
PutThread put: count[4] = 1485989449
PutThread put: count[5] = 621749895
PutThread put: count[6] = 437801478
PutThread put: count[7] = 1253412848
PutThread put: count[8] = 1311460812
PutThread put: count[9] = 1248942353
TakeThread1 is running ...
TakeThread2 is running ...
PutThread put: count[10] = 698743102
PutThread put: count[11] = -1936781178
TakeThread1 get count[0] = 1868845248
TakeThread2 get count[1] = -632455211
TakeThread1 get count[2] = 1793924123
PutThread put: count[12] = -112326037
TakeThread1 get count[3] = 721589803
PutThread put: count[13] = 1579579746
TakeThread2 get count[4] = 1485989449
PutThread put: count[14] = 767509425
TakeThread1 get count[5] = 621749895
PutThread put: count[15] = 1480592244
TakeThread2 get count[6] = 437801478
PutThread put: count[16] = 188800776
TakeThread1 get count[7] = 1253412848
PutThread put: count[17] = 1894067726
TakeThread2 get count[8] = 1311460812
PutThread put: count[18] = -558112254
TakeThread2 get count[9] = 1248942353
PutThread put: count[19] = 1587553626
TakeThread1 get count[10] = 698743102
TakeThread2 get count[11] = -1936781178
TakeThread1 get count[12] = -112326037
TakeThread2 get count[13] = 1579579746
TakeThread1 get count[14] = 767509425
TakeThread2 get count[15] = 1480592244
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39