# MyBatis源码骨架分析
# 一、MyBatis 源码概述
# 1、怎么下载 MyBatis 源码
MyBatis 源码下载地址:https://github.com/MyBatis/MyBatis-3
源码包导入过程:
- 下载
MyBatis的源码 - 检查
maven的版本,必须是 3.25 以上,建议使用maven的最新版本 MyBatis的工程是maven工程,在开发工具中导入,工程必须使用jdk1.8以上版本;- 把
MyBatis源码的pom文件中<optional>true</optional>,全部改为false(如果第5步执行报错的话,再修改这一步) - 在工程目录下执行
mvn clean install -Dmaven.test.skip=true,将当前工程安装到本地仓库(pdf插件报错的话,需要将这个插件屏蔽);注意:安装过程中会可能会有很多异常信息,只要不中断运行,请耐心等待; - 其他工程依赖此工程
# 2、源码架构分析
MyBatis 源码共 16 个模块,可以分成三层,如下图:
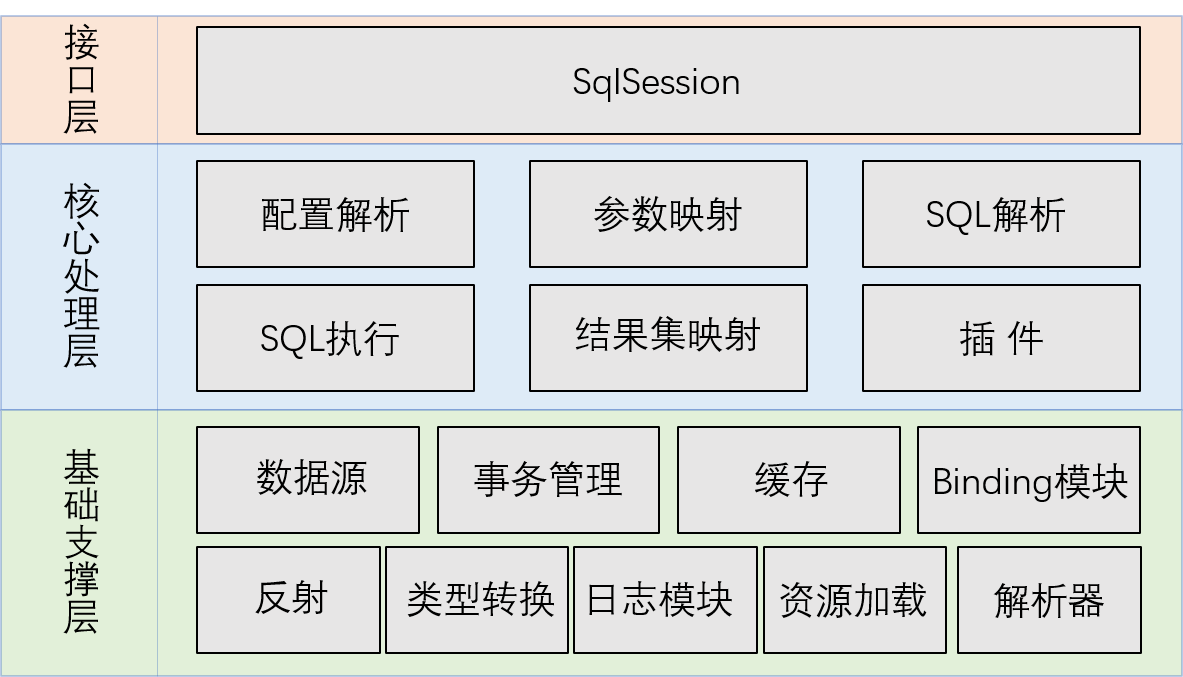
- 基础支撑层:技术组件专注于底层技术实现,通用性较强无业务含义;
- 核心处理层:业务组件专注
MyBatis的业务流程实现,依赖于基础支撑层; - 接口层:
MyBatis对外提供的访问接口,面向SqlSession编程;
系统为什么要分层?
- 代码和系统的可维护性更高。系统分层之后,每个层次都有自己的定位,每个层次内部的组件都有自己的分工,系统就会变得很清晰,维护起来非常明确;
- 方便开发团队分工和开发效率的提升;举个例子,
mybatis这么大的一个源码框架不可能是一个人开发的,他需要一个团队,团队之间肯定有分工,既然有了层次的划分,分工也会变得容易,开发人员可以专注于某一层的某一个模块的实现,专注力提升了,开发效率自然也会提升; - 提高系统的伸缩性和性能。系统分层之后,我们只要把层次之间的调用接口明确了,那我们就可以从逻辑上的分层变成物理上的分层。当系统并发量吞吐量上来了,怎么办?为了提高系统伸缩性和性能,我们可以把不同的层部署在不同服务器集群上,不同的组件放在不同的机器上,用多台机器去抗压力,这就提高了系统的性能。压力大的时候扩展节点加机器,压力小的时候,压缩节点减机器,系统的伸缩性就是这么来的;
# 3、外观模式(门面模式)
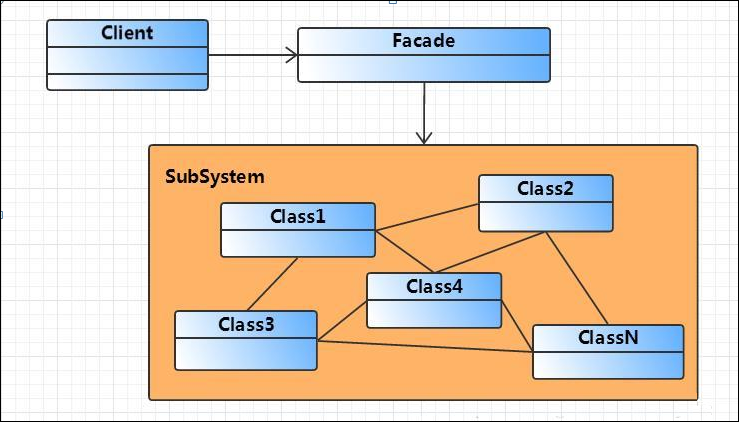
从源码的架构分析,特别是接口层的设计,可以看出来MyBatis的整体架构符合门面模式的。门面模式定义:提供了一个统一的接口,用来访问子系统中的一群接口。外观模式定义了一个高层接口,让子系统更容易使用。类图如下:

Facade 角色:提供一个外观接口,对外,它提供一个易于客户端访问的接口,对内,它可以访问子系统中的所有功能。
SubSystem(子系统)角色:子系统在整个系统中可以是一个或多个模块,每个模块都有若干类组成,这些类可能相互之间有着比较复杂的关系。
门面模式优点:
使复杂子系统的接口变的简单可用,减少了客户端对子系统的依赖,达到了解耦的效果;遵循了 OO 原则中的迪米特法则,对内封装具体细节,对外只暴露必要的接口。
- 门面模式使用场景:
- 一个复杂的模块或子系统提供一个供外界访问的接口
- 子系统相对独立 ― 外界对子系统的访问只要黑箱操作即可
# 4、面向对象设计需要遵循的六大设计原则
学习源码的目的除了学习编程的技巧、经验之外,最重要的是学习源码的设计的思想以及设计模式的灵活应用,因此在学习源码之前有必要对面向对象设计的几个原则先深入的去了解,让自己具备良好的设计思想和理念;
- 单一职责原则:一个类或者一个接口只负责唯一项职责,尽量设计出功能单一的接口;
- 依赖倒转原则:高层模块不应该依赖低层模块具体实现,解耦高层与低层。既面向接口编程,当实现发生变化时,只需提供新的实现类,不需要修改高层模块代码;
- 开放-封闭原则:程序对外扩展开放,对修改关闭;换句话说,当需求发生变化时,我们可以通过添加新模块来满足新需求,而不是通过修改原来的实现代码来满足新需求;
- 迪米特法则:一个对象应该对其他对象保持最少的了解,尽量降低类与类之间的耦合度;实现这个原则,要注意两个点,一方面在做类结构设计的时候尽量降低成员的访问权限,能用
private的尽量用private;另外在类之间,如果没有必要直接调用,就不要有依赖关系;这个法则强调的还是类之间的松耦合; - 里氏代换原则:所有引用基类(父类)的地方必须能透明地使用其子类的对象;
- 接口隔离原则:客户端不应该依赖它不需要的接口,一个类对另一个类的依赖应该建立在最小的接口上;
# 二、日志模块分析
# 1、日志模块需求分析
MyBatis没有提供日志的实现类,需要接入第三方的日志组件,但第三方日志组件都有各自的Log级别,且各不相同,而MyBatis统一提供了trace、debug、warn、error四个级别;- 自动扫描日志实现,并且第三方日志插件加载优先级如下:
slf4J→commonsLoging→Log4J2→Log4J→JdkLog; - 日志的使用要优雅的嵌入到主体功能中;
# 2、适配器模式
日志模块的第一个需求是一个典型的使用适配器模式的场景,适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁,将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作;类图如下:
- Target:目标角色,期待得到的接口.
- Adaptee:适配者角色,被适配的接口.
- Adapter:适配器角色,将源接口转换成目标接口.
适用场景:
当调用双方都不太容易修改的时候,为了复用现有组件可以使用适配器模式;在系统中接入第三方组件的时候经常被使用到;注意:如果系统中存在过多的适配器,会增加系统的复杂性,设计人员应考虑对系统进行重构;
MyBatis 日志模块是怎么使用适配器模式?实现如下:
- Target:目标角色,期待得到的接口。
org.apache.ibatis.logging.Log接口,对内提供了统一的日志接口; - Adaptee:适配者角色,被适配的接口。其他日志组件组件如
slf4J、commonsLoging、Log4J2等被包含在适配器中。 - Adapter:适配器角色,将源接口转换成目标接口。针对每个日志组件都提供了适配器,每个适配器都对特定的日志组件进行封装和转换; 如
Slf4jLoggerImpl、JakartaCommonsLoggingImpl等;
日志模块适配器结构类图:

总结:日志模块实现采用适配器模式,日志组件(Target)、适配器以及统一接口(Log 接口)定义清晰明确符合单一职责原则;同时,客户端在使用日志时,面向 Log 接口编程,不需要关心底层日志模块的实现,符合依赖倒转原则;最为重要的是,如果需要加入其他第三方日志框架,只需要扩展新的模块满足新需求,而不需要修改原有代码,这又符合了开闭原则;
# 3、怎么实现优先加载日志组件
见 org.apache.ibatis.logging.LogFactory 中的静态代码块,通过静态代码块确保第三方日志插件加载优先级如下:slf4J → commonsLoging → Log4J2 → Log4J → JdkLog;
public final class LogFactory {
/**
* Marker to be used by logging implementations that support markers.
*/
public static final String MARKER = "MYBATIS";
private static Constructor<? extends Log> logConstructor;
static {
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
private LogFactory() {
// disable construction
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 4、代理模式和动态代理
代理模式定义:给目标对象提供一个代理对象,并由代理对象控制对目标对象的引用;
目的:
- 通过引入代理对象的方式来间接访问目标对象,防止直接访问目标对象给系统带来的不必要复杂性;
- 通过代理对象对原有的业务增强;
代理模式类图:

代理模式有静态代理和动态代理两种实现方式。
# (1) 静态代理
这种代理方式需要代理对象和目标对象实现一样的接口。
优点:可以在不修改目标对象的前提下扩展目标对象的功能。
缺点:
- 冗余。由于代理对象要实现与目标对象一致的接口,会产生过多的代理类。
- 不易维护。一旦接口增加方法,目标对象与代理对象都要进行修改。
# (2) 动态代理
动态代理利用了 JDK API,动态地在内存中构建代理对象,从而实现对目标对象的代理功能。
动态代理又被称为 JDK 代理或接口代理。静态代理与动态代理的区别主要在:
- 静态代理在编译时就已经实现,编译完成后代理类是一个实际的
class文件 - 动态代理是在运行时动态生成的,即编译完成后没有实际的
class文件,而是在运行时动态生成类字节码,并加载到 JVM 中
注意:动态代理对象不需要实现接口,但是要求目标对象必须实现接口,否则不能使用动态代理。
JDK 中生成代理对象主要涉及两个类:
第一个类为 java.lang.reflect.Proxy,通过静态方法 newProxyInstance 生成代理对象,newProxyInstance 有3个参数,第一个是类加载器,第二个是被代理对象实现的所有接口的字节码数组,第三个是执行处理器,用户定义方法的增强规则,也就是下面的 InvocationHandler 类。
第二个为 java.lang.reflect.InvocationHandler 接口,通过 invoke() 方法对业务进行增强;
# 5、优雅的增强日志功能
首先搞清楚那些地方需要打印日志?通过对日志的观察,如下几个位置需要打日志:
- 在创建
prepareStatement时,打印执行的SQL语句; - 访问数据库时,打印参数的类型和值
- 查询出结构后,打印结果数据条数
因此在日志模块中有 BaseJdbcLogger、ConnectionLogger、PreparedStatementLogger 和 ResultSetLogger 通过动态代理负责在不同的位置打印日志;几个相关类的类图如下:

- BaseJdbcLogger:所有日志增强的抽象基类,用于记录
JDBC哪些方法需要增强,保存运行期间sql参数信息;
BaseJdbcLogger 一些重要的成员变量:
// 保存 prepareStatement 中常用的 set() 方法(占位符赋值)
protected static final Set<String> SET_METHODS;
// 保存 prepareStatement 中常用的执行 sql 语句的方法
protected static final Set<String> EXECUTE_METHODS = new HashSet<>();
// 保存 prepareStatement 中 set() 方法的键值对
private final Map<Object, Object> columnMap = new HashMap<>();
// 保存 prepareStatement 中 set() 方法的 key
private final List<Object> columnNames = new ArrayList<>();
// prepareStatement 中 set() 方法的的 value
private final List<Object> columnValues = new ArrayList<>();
2
3
4
5
6
7
8
9
10
11
12
- ConnectionLogger:负责打印连接信息和
SQL语句。通过动态代理,对connection对象进行增强,如果是调用prepareStatement()、prepareCall()、createStatement()的方法,打印要执行的sql语句并返回prepareStatement()的代理对象(PreparedStatementLogger),让prepareStatement也具备日志能力,打印参数;
@Override
public Object invoke(Object proxy, Method method, Object[] params)
throws Throwable {
try {
// 忽略掉从 Object 继承的方法
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
// 下面的方法需要增强
if ("prepareStatement".equals(method.getName()) || "prepareCall".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
// 对上面返回的 PreparedStatement 也需要增强
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("createStatement".equals(method.getName())) {
Statement stmt = (Statement) method.invoke(connection, params);
// 对上面返回的 Statement 也需要增强
stmt = StatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else {
return method.invoke(connection, params);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
/**
* Creates a logging version of a connection.
*
* @param conn
* the original connection
* @param statementLog
* the statement log
* @param queryStack
* the query stack
* @return the connection with logging
*/
public static Connection newInstance(Connection conn, Log statementLog, int queryStack) {
InvocationHandler handler = new ConnectionLogger(conn, statementLog, queryStack);
ClassLoader cl = Connection.class.getClassLoader();
return (Connection) Proxy.newProxyInstance(cl, new Class[]{Connection.class}, handler);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
- PreparedStatementLogger:对
prepareStatement对象增强,增强的点如下:
- 增强
PreparedStatement的setxxx方法将参数设置到columnMap、columnNames、columnValues,为打印参数做好准备; - 增强
PreparedStatement的execute相关方法,当方法执行时,通过动态代理打印参数,返回动态代理能力的resultSet; - 如果是查询,增强
PreparedStatement的getResultSet方法,返回动态代理能力的resultSet;如果是更新,直接打印影响的行数
@Override
public Object invoke(Object proxy, Method method, Object[] params) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
if (EXECUTE_METHODS.contains(method.getName())) {
if (isDebugEnabled()) {
// 打印参数
debug("Parameters: " + getParameterValueString(), true);
}
clearColumnInfo();
if ("executeQuery".equals(method.getName())) {
ResultSet rs = (ResultSet) method.invoke(statement, params);
return rs == null ? null : ResultSetLogger.newInstance(rs, statementLog, queryStack);
} else {
return method.invoke(statement, params);
}
} else if (SET_METHODS.contains(method.getName())) {
// 将参数设置到 columnMap、columnNames、columnValues,为打印参数做好准备
if ("setNull".equals(method.getName())) {
setColumn(params[0], null);
} else {
setColumn(params[0], params[1]);
}
return method.invoke(statement, params);
} else if ("getResultSet".equals(method.getName())) {
ResultSet rs = (ResultSet) method.invoke(statement, params);
return rs == null ? null : ResultSetLogger.newInstance(rs, statementLog, queryStack);
} else if ("getUpdateCount".equals(method.getName())) {
int updateCount = (Integer) method.invoke(statement, params);
if (updateCount != -1) {
debug(" Updates: " + updateCount, false);
}
return updateCount;
} else {
return method.invoke(statement, params);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
/**
* Creates a logging version of a PreparedStatement.
*
* @param stmt - the statement
* @param statementLog - the statement log
* @param queryStack - the query stack
* @return - the proxy
*/
public static PreparedStatement newInstance(PreparedStatement stmt, Log statementLog, int queryStack) {
InvocationHandler handler = new PreparedStatementLogger(stmt, statementLog, queryStack);
ClassLoader cl = PreparedStatement.class.getClassLoader();
return (PreparedStatement) Proxy.newProxyInstance(cl, new Class[]{PreparedStatement.class, CallableStatement.class}, handler);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
- ResultSetLogger:负责打印数据结果信息,对
next()方法增强;
@Override
public Object invoke(Object proxy, Method method, Object[] params) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
Object o = method.invoke(rs, params);
// 通过执行 result.next() 方法的结果值,判断是否还有数据
if ("next".equals(method.getName())) {
if ((Boolean) o) {
// 如果还有数据,计数器 rows 加1
rows++;
if (isTraceEnabled()) {
ResultSetMetaData rsmd = rs.getMetaData();
final int columnCount = rsmd.getColumnCount();
if (first) {
first = false;
printColumnHeaders(rsmd, columnCount);
}
printColumnValues(columnCount);
}
} else {
// 如果没有数据则打印查询出来的数据总条数
debug(" Total: " + rows, false);
}
}
clearColumnInfo();
return o;
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
/**
* Creates a logging version of a ResultSet.
*
* @param rs
* the ResultSet to proxy
* @param statementLog
* the statement log
* @param queryStack
* the query stack
* @return the ResultSet with logging
*/
public static ResultSet newInstance(ResultSet rs, Log statementLog, int queryStack) {
InvocationHandler handler = new ResultSetLogger(rs, statementLog, queryStack);
ClassLoader cl = ResultSet.class.getClassLoader();
return (ResultSet) Proxy.newProxyInstance(cl, new Class[]{ResultSet.class}, handler);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
上面这么多,都是日志功能的实现,那日志功能是怎么加入主体功能的?
既然在 Mybatis 中 Executor 才是访问数据库的组件,日志功能是在 Executor 中被嵌入的,具体代码在 org.apache.ibatis.executor.SimpleExecutor.prepareStatement(StatementHandler, Log)方法中,如下所示:
// 创建 Statement
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取 Connection 对象的动态代理,添加日志能力
Connection connection = getConnection(statementLog);
// 通过不同的 StatementHandler,利用 connection 创建 (prepare)Statement
stmt = handler.prepare(connection, transaction.getTimeout());
// 使用 parameterHandler 处理占位符
handler.parameterize(stmt);
return stmt;
}
2
3
4
5
6
7
8
9
10
11
然后在 getConnection() 中获取到了增强的 Connection 对象:
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) {
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
return connection;
}
}
2
3
4
5
6
7
8
修改之前的工厂,让它依赖我们下载好的源码,运行过程中可能会报错,需要添加以下两个依赖:
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.21.0-GA</version>
</dependency>
<dependency>
<groupId>ognl</groupId>
<artifactId>ognl</artifactId>
<version>3.1.12</version>
</dependency>
2
3
4
5
6
7
8
9
10
上面的是解决 Cannot enable lazy loading because Javassist is not available. Add Javassist 这个异常的。
下面的解决 java.lang.NoClassDefFoundError: ognl/PropertyAccessor 这个异常的。
# 三、数据源模块分析
数据源模块重点讲解数据源的创建和数据库连接池的源码分析;数据源创建比较负责,对于复杂对象的创建,可以考虑使用工厂模式来优化,接下来介绍下简单工厂模式和工厂模式;
# 1、简单工厂模式
简单工厂属于类的创建型设计模式,通过专门定义一个类来负责创建其它类的实例,被创建的实例通常都具有共同的父类。类图如下:
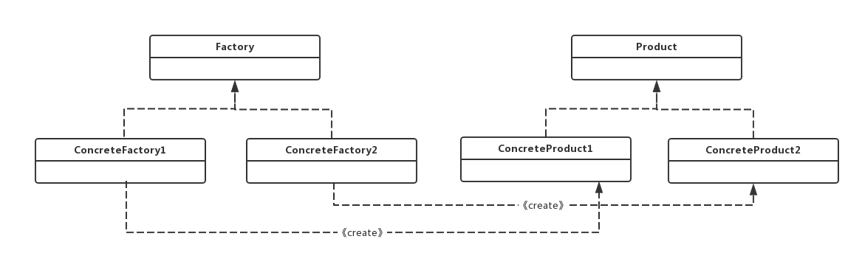
- 工厂接口(
Factory):简单工厂的接口,定义了创建产品的方法,具体的工厂类必须实现这个接口; - 工厂角色(
ConcreteFactory):这是简单工厂模式的核心,由它负责创建全部的类的内部逻辑。工厂类被外界调用,创建所须要的产品对象。 - 抽象(
Product)产品角色:简单工厂模式所创建的全部对象的父类,注意,这里的父类能够是接口也能够是抽象类,它负责描写叙述全部实例所共同拥有的公共接口。 - 详细产品(
Concrete Product)角色:简单工厂所创建的详细实例对象,这些详细的产品往往都拥有共同的父类。
简单工厂适用场景:
简单工厂模式将对象的创建和使用进行解耦,并屏蔽了创建对象可能的复杂过程,但由于创建对象的逻辑集中工厂类当中,所以简单工厂适合于产品类型不多、需求变化不频繁的场景;
简单工厂模式的缺点:
工厂类负责了所有产品的实例化,违反单一职责原则,如果产品类型比较多工厂类的代码量会比较大,不利于类的可读性和扩展性;。另外当有新的产品类型加入时,必须修改工厂类原有的代码,这又违反了开闭原则;
# 2、工厂模式
工厂模式属于创建型模式,它提供了一种创建对象的最佳方式。定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。类图如下:
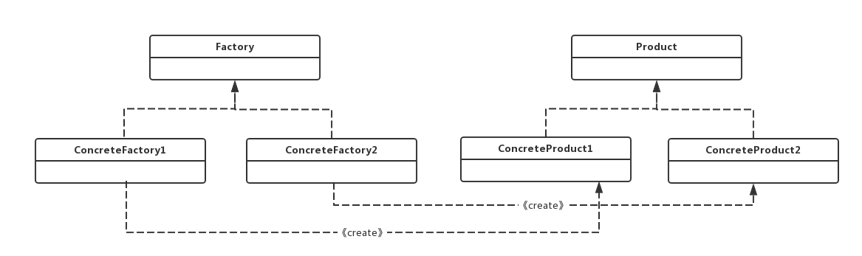
- 产品接口(
Product):产品接口用于定义产品类的功能,具体工厂类产生的所有产品都必须实现这个接口。调用者与产品接口直接交互,这是调用者最关心的接口; - 具体产品类(
ConcreteProduct):实现产品接口的实现类,具体产品类中定义了具体的业务逻辑; - 工厂接口(
Factory):工厂接口是工厂方法模式的核心接口,调用者会直接和工厂接口交互用于获取具体的产品实现类; - 具体工厂类(
ConcreteFactory):是工厂接口的实现类,用于实例化产品对象,不同的具体工厂类会根据需求实例化不同的产品实现类;
为什么要使用工厂模式?
答:对象可以通过 new 关键字、反射、clone() 等方式创建,也可以通过工厂模式创建。对于复杂对象,使用 new 关键字、反射、clone() 等方式创建存在如下缺点:
- 对象创建和对象使用的职责耦合在一起,违反单一原则;
- 当业务扩展时,必须修改代业务代码,违反了开闭原则;
而使用工厂模式将对象的创建和使用进行解耦,并屏蔽了创建对象可能的复杂过程,相对简单工厂模式,又具备更好的扩展性和可维护性,优点具体如下:
- 把对象的创建和使用的过程分开,对象创建和对象使用使用的职责解耦;
- 如果创建对象的过程很复杂,创建过程统一到工厂里管理,既减少了重复代码,也方便以后对创建过程的修改维护;
- 当业务扩展时,只需要增加工厂子类,符合开闭原则;
# 3、数据源的创建
数据源对象是比较复杂的对象,其创建过程相对比较复杂,对于 MyBatis 创建一个数据源,具体来讲有如下难点:
- 常见的数据源组件都实现了
javax.sql.DataSource接口; MyBatis不但要能集成第三方的数据源组件,自身也提供了数据源的实现;- 一般情况下,数据源的初始化过程参数较多,比较复杂;
综上所述,数据源的创建是一个典型使用工厂模式的场景,实现类图如下所示:
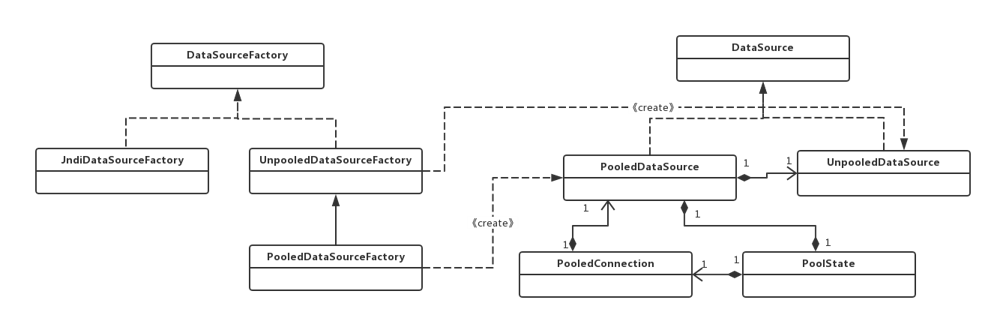
- DataSource:数据源接口,
JDBC标准规范之一,定义了获取获取Connection的方法; - UnPooledDataSource:不带连接池的数据源,获取连接的方式和手动通过
JDBC获取连接的方式是一样的; - PooledDataSource:带连接池的数据源,提高连接资源的复用性,避免频繁创建、关闭连接资源带来的开销;
- DataSourceFactory:工厂接口,定义了创建
Datasource的方法; - UnpooledDataSourceFactory:工厂接口的实现类之一,用于创建
UnpooledDataSource(不带连接池的数据源); - PooledDataSourceFactory:工厂接口的实现类之一,用于创建
PooledDataSource(带连接池的数据源);
# 4、数据库连接池技术解析
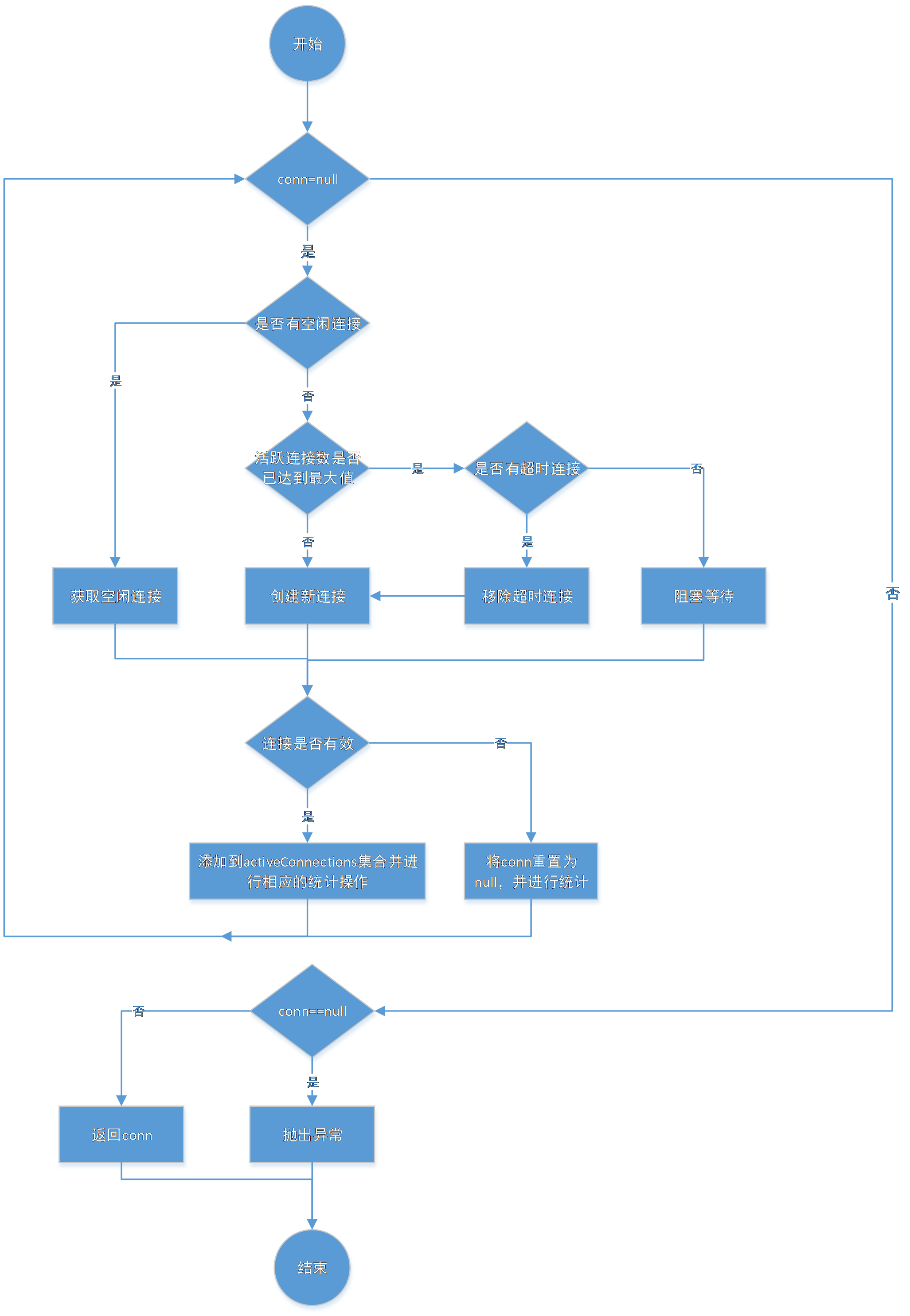
数据库连接池技术是提升数据库访问效率常用的手段,使用连接池可以提高连接资源的复用性,避免频繁创建、关闭连接资源带来的开销,池化技术也是大厂高频面试题。MyBatis 内部就带了一个连接池的实现,接下来重点解析连接池技术的数据结构和算法;先重点分析下跟连接池相关的关键类:
- PooledDataSource:一个简单,同步的、线程安全的数据库连接池
- PooledConnection:使用动态代理封装了真正的数据库连接对象,在连接使用之前和关闭时进行增强;
- PoolState:用于管理
PooledConnection对象状态的组件,通过两个list分别管理空闲状态的连接资源和活跃状态的连接资源,如下图,需要注意的是这两个List使用ArrayList实现,存在并发安全的问题,因此在使用时,注意加上同步控制;
重点解析获取资源和回收资源的流程,获取连接资源的过程如下图:
回收连接资源的过程如下图:

# 四、缓存模块分析
# 1、需求分析
MyBatis 缓存模块需满足如下需求:
MyBatis缓存的实现是基于Map的,从缓存里面读写数据是缓存模块的核心基础功能;- 除核心功能之外,有很多额外的附加功能,如:防止缓存击穿,添加缓存清空策略(
fifo、lru)、序列化功能、日志能力、定时清空能力等; - 附加功能可以以任意的组合附加到核心基础功能之上;
基于 Map 核心缓存能力,将阻塞、清空策略、序列化、日志等等能力以任意组合的方式优雅的增强是 Mybatis 缓存模块实现最大的难题,用动态代理或者继承的方式扩展多种附加能力的传统方式存在以下问题:这些方式是静态的,用户不能控制增加行为的方式和时机;另外,新功能的存在多种组合,使用继承可能导致大量子类存在。综上,MyBtis 缓存模块采用了装饰器模式实现了缓存模块;
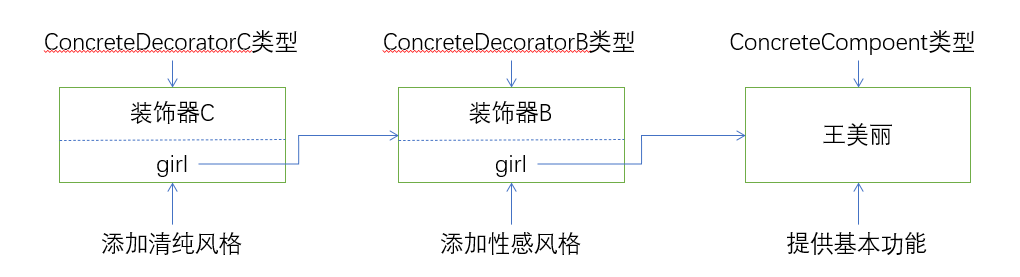
# 2、装饰器模式
装饰器模式是一种用于代替继承的技术,无需通过继承增加子类就能扩展对象的新功能。使用对象的关联关系代替继承关系,更加灵活,同时避免类型体系的快速膨胀。装饰器 UML 类图如下:

- 组件(Component):组件接口定义了全部组件类和装饰器实现的行为;
- 组件实现类(ConcreteComponent):实现
Component接口,组件实现类就是被装饰器装饰的原始对象,新功能或者附加功能都是通过装饰器添加到该类的对象上的; - 装饰器抽象类(Decorator):实现
Component接口的抽象类,在其中封装了一个Component对象,也就是被装饰的对象; - 具体装饰器类(ConcreteDecorator):该实现类要向被装饰的对象添加某些功能;
装饰器模式通俗易懂图示:
装饰器相对于继承,装饰器模式灵活性更强,扩展性更强:
- 灵活性:装饰器模式将功能切分成一个个独立的装饰器,在运行期可以根据需要动态的添加功能,甚至对添加的新功能进行自由的组合;
- 扩展性:当有新功能要添加的时候,只需要添加新的装饰器实现类,然后通过组合方式添加这个新装饰器,无需修改已有代码,符合开闭原则;
装饰器模式使用举例:
IO中输入流和输出流的设计
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream("c://a.txt")));
- 对网络爬虫的自定义增强,可增强的功能包括:多线程能力、缓存、自动生成报表、黑白名单、
random触发等
# 3、装饰器在缓存模块的使用
MyBatis 缓存模块是一个经典的使用装饰器实现的模块,类图如下:

- Cache:Cache 接口是缓存模块的核心接口,定义了缓存的基本操作;
- PerpetualCache:在缓存模块中扮演
ConcreteComponent角色,使用HashMap来实现cache的相关操作; - BlockingCache:阻塞版本的缓存装饰器,保证只有一个线程到数据库去查找指定的
key对应的数据;
BlockingCache 是阻塞版本的缓存装饰器,这个装饰器通过 ConcurrentHashMap 对锁的粒度进行了控制,提高加锁后系统代码运行的效率(注:缓存雪崩的问题可以使用细粒度锁的方式提升锁性能),源码分析见:org.apache.ibatis.cache.decorators.BlockingCache;除了 BlockingCache 之外,缓存模块还有其他的装饰器如:
- LoggingCache:日志能力的缓存;
- ScheduledCache:定时清空的缓存;
- BlockingCache:阻塞式缓存;
- SerializedCache:序列化能力的缓存;
- SynchronizedCache:进行同步控制的缓存;
# Mybatis 的缓存功能使用 HashMap 实现会不会出现并发安全的问题?
答:MyBatis 的缓存分为一级缓存、二级缓存。二级缓存是多个会话共享的缓存,确实会出现并发安全的问题,因此 MyBatis 在初始化二级缓存时,会给二级缓存默认加上 SynchronizedCache 装饰器的增强,在对共享数据 HashMap 操作时进行同步控制,所以二级缓存不会出现并发安全问题;而一级缓存是会话独享的,不会出现多个线程同时操作缓存数据的场景,因此一级缓存也不会出现并发安全的问题;
# 4、缓存的唯一标识 CacheKey
MyBatis 中涉及到动态 SQL 的原因,缓存项的 key 不能仅仅通过一个 String 来表示,所以通过 CacheKey 来封装缓存的 Key 值,CacheKey 可以封装多个影响缓存项的因素;判断两个 CacheKey 是否相同关键是比较两个对象的hash值是否一致;构成 CacheKey 对象的要素包括:
mappedStatment的id- 指定查询结果集的范围(分页信息)
- 查询所使用的
SQL语句 - 用户传递给
SQL语句的实际参数值
CacheKey 中 update() 方法和 equals() 方法是进行比较时非常重要的两个方法:
- update 方法:用于添加构成
CacheKey对象的要素,每添加上面4个元素的其中一个,就会对hashcode、checksum、count以及updateList进行更新;
public void update(Object object) {
// 获取object的hash值
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
// 更新count、checksum以及hashcode的值
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;
// 将对象添加到updateList中
updateList.add(object);
}
2
3
4
5
6
7
8
9
10
11
12
- equals 方法:用于比较两个元素是否相等。首先比较
hashcode、checksum、count是否相等,如果这三个值相等,会循环比较updateList中每个元素的hashCode是否一致;按照这种方式判断两个对象是否相等,一方面能很严格的判断是否一致避免出现误判,另外一方面能提高比较的效率;
@Override
public boolean equals(Object object) {
// 比较是不是同一个对象
if (this == object) {
return true;
}
// 是否类型相同
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
// hashcode 是否相同
if (hashcode != cacheKey.hashcode) {
return false;
}
// checksum 是否相同
if (checksum != cacheKey.checksum) {
return false;
}
// count 是否相同
if (count != cacheKey.count) {
return false;
}
// 以上都相同,才按顺序比较 updateList 中元素的 hash 值是否一致
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 5、反射模块分析
反射是 Mybatis 模块中类最多的模块,通过反射实现了 POJO 对象的实例化和 POJO 的属性赋值,相对 JDK 自带的反射功能,MyBatis 的反射模块功能更为强大,性能更高;反射模块关键的几个类如下:
- ObjectFactory:
MyBatis每次创建结果对象的新实例时,它都会使用对象工厂(ObjectFactory)去构建POJO;
ObjectFactory: 接口中最终要的两个方法是:
/**
* Creates a new object with default constructor.
*
* @param <T>
* the generic type
* @param type
* Object type
* @return the t
*/
// 通过无参构造函数创建指定类的对象
<T> T create(Class<T> type);
2
3
4
5
6
7
8
9
10
11
默认是的实现是 DefaultObjectFactory:
@Override
public <T> T create(Class<T> type) {
return create(type, null, null);
}
@SuppressWarnings("unchecked")
@Override
public <T> T create(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
// 判断类是不是集合类,如果是集合类指定具体的实现类
Class<?> classToCreate = resolveInterface(type);
// we know types are assignable
return (T) instantiateClass(classToCreate, constructorArgTypes, constructorArgs);
}
// 根据传过来的类型,构造方法,和构造方法的参数实例化对象
private <T> T instantiateClass(Class<T> type, List<Class<?>> constructorArgTypes, List<Object> constructorArgs) {
try {
Constructor<T> constructor;
// 通过无参构造函数创建对象
if (constructorArgTypes == null || constructorArgs == null) {
constructor = type.getDeclaredConstructor();
try {
return constructor.newInstance();
} catch (IllegalAccessException e) {
if (Reflector.canControlMemberAccessible()) {
constructor.setAccessible(true);
return constructor.newInstance();
} else {
throw e;
}
}
}
// 根据指定的参数列表查找构造函数,并实例化对象
constructor = type.getDeclaredConstructor(constructorArgTypes.toArray(new Class[0]));
try {
return constructor.newInstance(constructorArgs.toArray(new Object[0]));
} catch (IllegalAccessException e) {
if (Reflector.canControlMemberAccessible()) {
constructor.setAccessible(true);
return constructor.newInstance(constructorArgs.toArray(new Object[0]));
} else {
throw e;
}
}
} catch (Exception e) {
String argTypes = Optional.ofNullable(constructorArgTypes).orElseGet(Collections::emptyList)
.stream().map(Class::getSimpleName).collect(Collectors.joining(","));
String argValues = Optional.ofNullable(constructorArgs).orElseGet(Collections::emptyList)
.stream().map(String::valueOf).collect(Collectors.joining(","));
throw new ReflectionException("Error instantiating " + type + " with invalid types (" + argTypes + ") or values (" + argValues + "). Cause: " + e, e);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
通过暴力反射帮助我们生成实例对象。
- ReflectorFactory:创建
Reflector的工厂类,Reflector是MyBatis反射模块的基础,每个Reflector对象都对应一个类,在其中缓存了反射操作所需要的类元信息;
元信息就是实体类的字段和成员方法。Reflector 的属性和构造方法:
// 对应的 class
private final Class<?> type;
// 可读属性的名称集合,存在 get()方法即可读
private final String[] writablePropertyNames;
// 可写属性的名称集合,存在 set() 方法即可写
private final Map<String, Invoker> setMethods = new HashMap<>();
// 保存属性相关的 set() 方法
private final Map<String, Invoker> getMethods = new HashMap<>();
// 保存属性相关的 get() 方法
private final String[] readablePropertyNames;
// 保存属性相关的 set() 方法入参类型
private final Map<String, Class<?>> setTypes = new HashMap<>();
// 保存属性相关的 get() 方法返回类型
private final Map<String, Class<?>> getTypes = new HashMap<>();
// class 默认的构造函数
private Constructor<?> defaultConstructor;
// 记录所有属性的名称集合
private Map<String, String> caseInsensitivePropertyMap = new HashMap<>();
public Reflector(Class<?> clazz) {
type = clazz;
// 获取 clazz 的默认构造函数
addDefaultConstructor(clazz);
// 处理 clazz 中的 get() 方法信息,填充 getMethods、getTypes
addGetMethods(clazz);
// 处理 clazz 中的 set() 方法信息,填充 setMethods、setTypes
addSetMethods(clazz);
// 处理没有 get()、set() 方法的属性
addFields(clazz);
// 根据 get()、set() 方法初始化可读属性集合和可写属性集合
readablePropertyNames = getMethods.keySet().toArray(new String[0]);
writablePropertyNames = setMethods.keySet().toArray(new String[0]);
// 初始化 caseInsensitivePropertyMap
for (String propName : readablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
for (String propName : writablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
MyBatis 强大之处在于,即使你定义的 pojo 类的成员没有 get() 和 set() 方法,它也会帮助你生成对应的 get() 和 set() 方法。
在 addFields() 方法中:
private void addFields(Class<?> clazz) {
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
if (!setMethods.containsKey(field.getName())) {
// issue #379 - removed the check for final because JDK 1.5 allows
// modification of final fields through reflection (JSR-133). (JGB)
// pr #16 - final static can only be set by the classloader
int modifiers = field.getModifiers();
if (!(Modifier.isFinal(modifiers) && Modifier.isStatic(modifiers))) {
// 这里给没有 set() 方法的属性,生成一个 set() 方法
addSetField(field);
}
}
if (!getMethods.containsKey(field.getName())) {
// 这里给没有 get() 方法的属性,生成一个 get() 方法
addGetField(field);
}
}
if (clazz.getSuperclass() != null) {
addFields(clazz.getSuperclass());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
它会检测是属性如果没有 get() 和 set() 方法,就会帮助生成一个对应的方法。
private void addSetField(Field field) {
if (isValidPropertyName(field.getName())) {
setMethods.put(field.getName(), new SetFieldInvoker(field));
Type fieldType = TypeParameterResolver.resolveFieldType(field, type);
setTypes.put(field.getName(), typeToClass(fieldType));
}
}
private void addGetField(Field field) {
if (isValidPropertyName(field.getName())) {
getMethods.put(field.getName(), new GetFieldInvoker(field));
Type fieldType = TypeParameterResolver.resolveFieldType(field, type);
getTypes.put(field.getName(), typeToClass(fieldType));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
其中 SetFieldInvoker 和 GetFieldInvoker 类就是负责生成 set() 和 get() 方法的类。
ReflectorFactory 的默认实现类是 DefaultReflectorFactory
// reflect 的简单工厂类
public class DefaultReflectorFactory implements ReflectorFactory {
private boolean classCacheEnabled = true;
// 用户缓存 pojo 的元数据,避免反射性能较低的问题
private final ConcurrentMap<Class<?>, Reflector> reflectorMap = new ConcurrentHashMap<>();
public DefaultReflectorFactory() {
}
@Override
public boolean isClassCacheEnabled() {
return classCacheEnabled;
}
@Override
public void setClassCacheEnabled(boolean classCacheEnabled) {
this.classCacheEnabled = classCacheEnabled;
}
@Override
public Reflector findForClass(Class<?> type) {
if (classCacheEnabled) {
// synchronized (type) removed see issue #461
return reflectorMap.computeIfAbsent(type, Reflector::new);
} else {
return new Reflector(type);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
DefaultReflectorFactory 会在启动的时候,将所有的 pojo 的元数据,缓存到 ConcurrentHashMap 中,解决了反射性能低的问题。
演示通过 Reflector 获取元数据信息:
@Test
public void reflectorTest() {
// 反射工具类初始化
ObjectFactory objectFactory = new DefaultObjectFactory();
TUser user = objectFactory.create(TUser.class);
ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
MetaObject metaObject = MetaObject.forObject(user, objectFactory, objectWrapperFactory, reflectorFactory);
// 使用 Reflector 读取类元信息
Reflector findForClass = reflectorFactory.findForClass(TUser.class);
Constructor<?> defaultConstructor = findForClass.getDefaultConstructor();
String[] getablePropertyNames = findForClass.getGetablePropertyNames();
String[] setablePropertyNames = findForClass.getSetablePropertyNames();
System.out.println(defaultConstructor.getName());
System.out.println(Arrays.toString(getablePropertyNames));
System.out.println(Arrays.toString(setablePropertyNames));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ObjectWrapper:对对象的包装,抽象了对象的属性信息,他定义了一系列查询对象属性信息的方法,以及更新属性的方法;
ObjectWrapperFactory:
ObjectWrapper的工厂类,用于创建ObjectWrapper;
public interface ObjectWrapper {
// 获取对象指定属性的值
Object get(PropertyTokenizer prop);
// 设置对象指定属性的值
void set(PropertyTokenizer prop, Object value);
String findProperty(String name, boolean useCamelCaseMapping);
String[] getGetterNames();
String[] getSetterNames();
Class<?> getSetterType(String name);
Class<?> getGetterType(String name);
boolean hasSetter(String name);
boolean hasGetter(String name);
MetaObject instantiatePropertyValue(String name, PropertyTokenizer prop, ObjectFactory objectFactory);
// 判断当前对象是否为集合
boolean isCollection();
// 当前集合添加一个元素
void add(Object element);
// 当前集合添加另外一个集合
<E> void addAll(List<E> element);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
ObjectWrapper 的默认实现类是:BeanWrapper,BeanWrapper 封装了两个非常重要的数据:
// 实例对象
private final Object object;
// 类的元数据
private final MetaClass metaClass;
2
3
4
BeanWrapper 实现的 set() 方法,用户给字段赋值:
@Override
public void set(PropertyTokenizer prop, Object value) {
// 判断是否是容器
if (prop.getIndex() != null) {
Object collection = resolveCollection(prop, object);
setCollectionValue(prop, collection, value);
} else {
setBeanProperty(prop, object, value);
}
}
2
3
4
5
6
7
8
9
10
判断不为容器的时候,执行 setBeanProperty() 进行赋值:
private void setBeanProperty(PropertyTokenizer prop, Object object, Object value) {
try {
// 获取元数据的 set() 方法
Invoker method = metaClass.getSetInvoker(prop.getName());
Object[] params = {value};
try {
// 将这个属性设置成 value
method.invoke(object, params);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} catch (Throwable t) {
throw new ReflectionException("Could not set property '" + prop.getName() + "' of '" + object.getClass() + "' with value '" + value + "' Cause: " + t.toString(), t);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
演示通过 ObjectWrapper 给 bean 的属性赋值:
@Test
public void objectWrapperTest() {
// 反射工具类初始化
ObjectFactory objectFactory = new DefaultObjectFactory();
TUser user = objectFactory.create(TUser.class);
ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
MetaObject metaObject = MetaObject.forObject(user, objectFactory, objectWrapperFactory, reflectorFactory);
// 使用ObjectWrapper读取对象信息,并对对象属性进行赋值操作
TUser userTemp = new TUser();
ObjectWrapper wrapperForUser = new BeanWrapper(metaObject, userTemp);
String[] getterNames = wrapperForUser.getGetterNames();
String[] setterNames = wrapperForUser.getSetterNames();
System.out.println(Arrays.toString(getterNames));
System.out.println(Arrays.toString(setterNames));
PropertyTokenizer prop = new PropertyTokenizer("userName");
wrapperForUser.set(prop, "lison");
System.out.println(userTemp);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- MetaObject:封装了对象元信息,包装了
MyBatis中五个核心的反射类。也是提供给外部使用的反射工具类,可以利用它可以读取或者修改对象的属性信息;MetaObject的类结构如下所示:

模拟从数据库读取数据并转化成对象:
@Test
public void metaObjectTest() {
// 反射工具类初始化
ObjectFactory objectFactory = new DefaultObjectFactory();
TUser user = objectFactory.create(TUser.class);
ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
MetaObject metaObject = MetaObject.forObject(user, objectFactory, objectWrapperFactory, reflectorFactory);
// 模拟数据库行数据转化成对象
// 1.模拟从数据库读取数据
Map<String, Object> dbResult = new HashMap<>();
dbResult.put("id", 1);
dbResult.put("userName", "lison");
dbResult.put("realName", "李晓宇");
TPosition tp = new TPosition();
tp.setId(1);
dbResult.put("position_id", tp);
// 2.模拟映射关系
Map<String, String> mapper = new HashMap<>();
mapper.put("id", "id");
mapper.put("userName", "userName");
mapper.put("realName", "realName");
mapper.put("position", "position_id");
// 3.使用反射工具类将行数据转换成 pojo
BeanWrapper objectWrapper = (BeanWrapper) metaObject.getObjectWrapper();
Set<Map.Entry<String, String>> entrySet = mapper.entrySet();
// 遍历映射关系
for (Map.Entry<String, String> colInfo : entrySet) {
// 获取 pojo 的字段名称
String propName = colInfo.getKey();
// 模拟从数据库中加载数据对应列的值
Object propValue = dbResult.get(colInfo.getValue());
PropertyTokenizer proTokenizer = new PropertyTokenizer(propName);
// 将数据库的值赋值到 pojo 的字段中
objectWrapper.set(proTokenizer, propValue);
}
System.out.println(metaObject.getOriginalObject());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41