# MySQL业务设计
阅读量 loading
# 一、逻辑设计
# 1、范式设计
# (1) 数据库设计的第一大范式
- 数据库表中的所有字段都只具有单一属性
- 单一属性的列是由基本数据类型所构成的
- 设计出来的表都是简单的二维表
下面这个表一个字段就包含了多个属性:

所以不满足第一范式,应当这样:
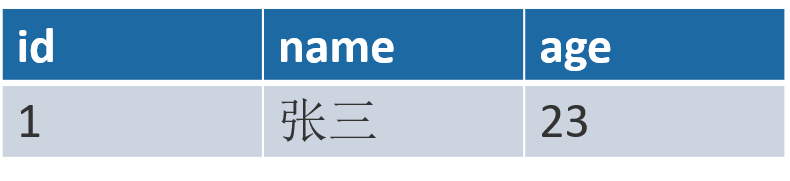
# (2) 数据库设计的第二大范式
要求表中只具有一个业务主键,也就是说符合第二范式的表不能存在非主键列只对部分主键的依赖关系
不满足:
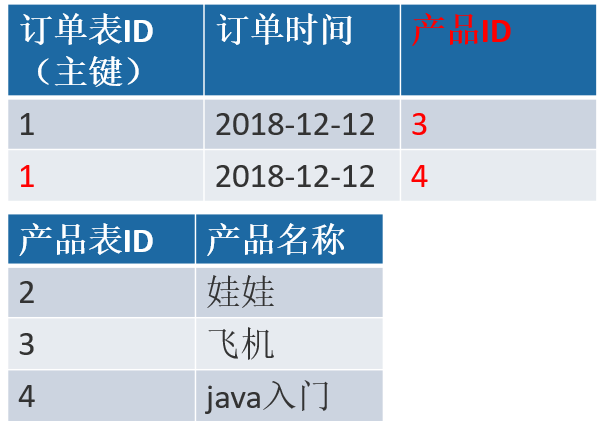
一个订单有多个产品,所以订单的主键为【订单 ID】和【产品 ID】组成的联合主键,这样 2个组件不符合第二范式,而且产品 ID 和订单 ID 没有强关联,故,把订单表进行拆分为订单表与订单与商品的中间表
满足:
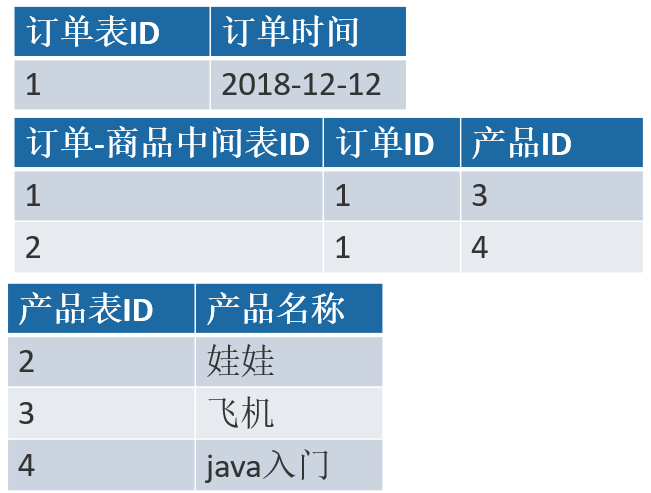
# (3) 数据库设计的第三大范式
指每一个非非主属性既不部分依赖于也不传递依赖于业务主键,也就是在第二范式的基础上相处了非主键对主键的传递依赖
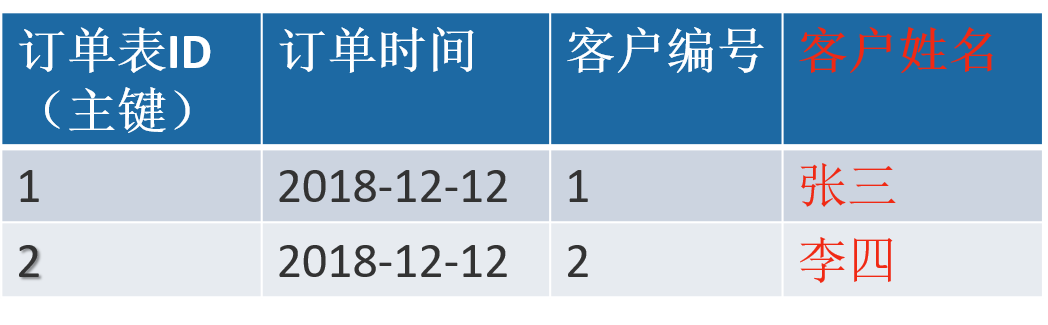
其中:
客户编号 和订单编号管理 关联
客户姓名 和订单编号管理 关联
客户编号 和 客户姓名 关联
如果客户编号发生改变,用户姓名也会改变,这样不符合第三大范式,应该把客户姓名这一列删除
# (4) 范式设计实战
按要求设计一个电子商务网站的数据库结构
- 本网站只销售图书类产品
- 需要具备以下功能
用户登陆、商品展示、供应商管理、用户管理、商品管理、订单销售
最终满足三大范式设计的表应当是这样子的:
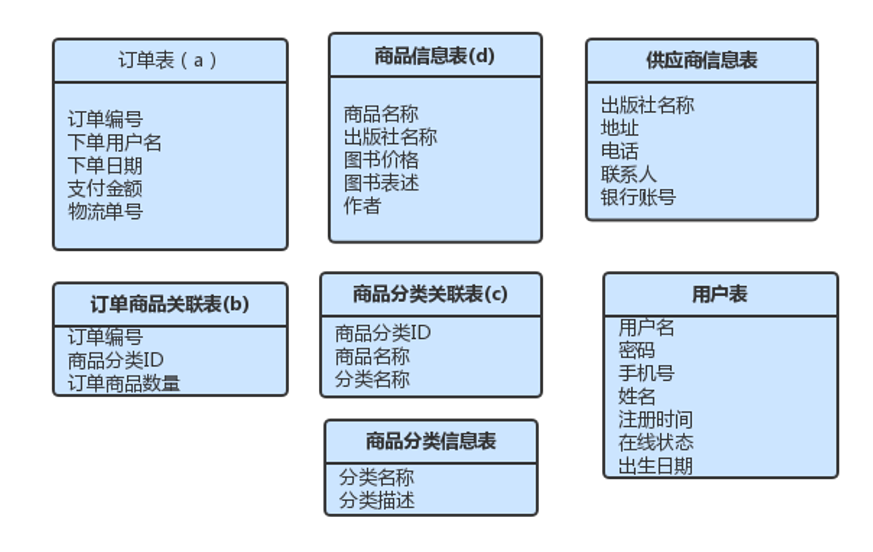
此时如果想要查询一个用户的订单总金额就会管理很多张表,这非常影响查询的性能。
# 2、反范式设计
- 反范式化是针对范式化而言得,在前面介绍了数据库设计得范式
- 所谓得反范式化就是为了性能和读取效率得考虑而适当得对数据库设计范式得要求进 行违反
- 允许存在少量得冗余,换句话来说反范式化就是使用空间来换取时间
# 3、总结
# (1) 范式化优缺点
优点:
- 可以尽量得减少数据冗余
- 范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化的表更小
缺点:
- 对于查询需要对多个表进行关联
- 更难进行索引优化
# (2) 反范式优缺点
优点:
- 可以减少表的关联
- 可以更好的进行索引优化
缺点:
- 存在数据冗余及数据维护异常
- 对数据的修改需要更多的成本
# 二、物理设计
- 定义数据库、表及字段的命名规范
- 选择合适的存储引擎
- 为表中的字段选择合适的数据类型
- 建立数据库结构
# 1、命名规范
# (1) 数据库、表、字段的命名要遵守可读性原则
使用大小写来格式化的库对象名字以获得良好的可读性
例如:使用 custAddress 而不是 custaddress 来提高可读性。
# (2) 数据库、表、字段的命名要遵守表意性原则
对象的名字应该能够描述它所表示的对象
例如:
对于表,表的名称应该能够体现表中存储的数据内容;对于存储过程存储过程应该能够体现存储过程的功能。
# (3) 数据库、表、字段的命名要遵守长名原则
尽可能少使用或者不使用缩写
# 2、存储引擎选择
除非有特别需求,一般都是用 InnoDB 引擎
# 3、数据类型选择
当一个列可以选择多种数据类型时
- 优先考虑数字类型
- 其次是日期、时间类型
- 最后是字符类型
- 对于相同级别的数据类型,应该优先选择占用空间小的数据类型
← MySQL锁与事务的分析 MySQL慢查询 →