# MySQL体系架构
# 一、体系
# 1、连接层
当 MySQL 启动(MySQL 服务器就是一个进程),等待客户端连接,每一个客户端连接请求,服务器都会新建一个线程处理(如果是线程池的话,则是分配一个空的线程),每个线程独立,拥有各自的内存处理空间。
# 2、SQL处理层
# (1) 缓存
查询是否开启缓存:SELECT @@query_cache_type
查询缓存的大小:SELECT @@query_cache_size
# (2) 解析查询
一个 sql 语句通常如下:

实际的解析顺序如下:
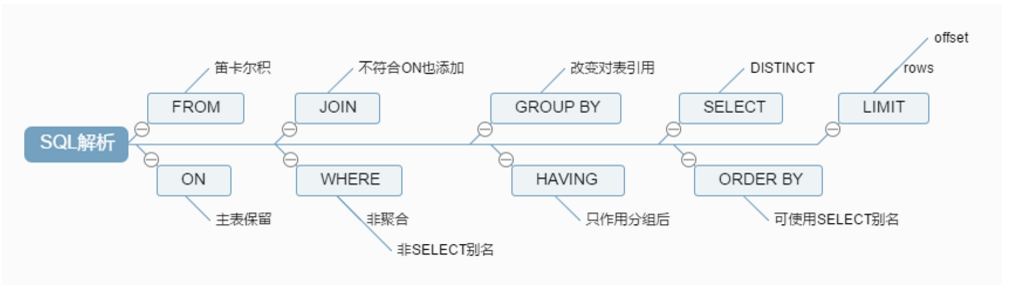
# (3) 优化
EXPLAIN SELECT * FROM account WHERE name = ''
观察执行计划的 Extra 字段是:Using where,说明这个 sql 语句使用到了 where 语句查询。
EXPLAIN SELECT * FROM account WHERE 1 = 1
此时 Extra 字段是空的,说明这里虽然写了 WHERE 1 = 1,但是实际上并不是一个真正的 where 语句查询。
EXPLAIN SELECT * FROM account WHERE id is not null
此时 Extra 字段是:Impossible WHERE,因为主键 id 是不可能为 null 的,所以这里是一个不可能的 WHERE 语句查询。
EXPLAIN SELECT * FROM account t WHERE t.id IN (SELECT t2.id FROM account t2);
执行上面这个语句会产生一条 warning ,使用 SHOW warnings 可以看出,它提示我们的上面的 sql 其实和下面这个 sql 的是等价的:
SELECT
t.id,
t.name,
t.balance
FROM
account t
JOIN account t2
WHERE
t.id = t2.id
2
3
4
5
6
7
8
9
# 二、逻辑架构
在 mysql 中其实还有个 schema 的概念,这概念没什么太多作用,只是为了兼容其他数据库,所以也提出了这个。在 mysql 中 database 和 schema 是等价的。
CREATE DATABASE demo;
DROP SCHEMA demo;
2
使用 DATABASE 创建的库,使用 SCHEMA 来删除也会将库删除。
# 三、物理存储结构
使用这个命令可以看到 mysql 数据都存在哪里:
SHOW VARIABLES LIKE 'datadir'
进入这个路径后,可以看出,这里面存了一个个文件夹,是和数据库的名字是一一对应的。再进入每一个文件夹,每一张表都对应一个 .frm 和 .ibd 文件。
.frm 就是表结构文件,.ibd 表是的使用 innoDB 引擎创建的表。
如果想看到 .frm 的文件内容,需要安装一个工具:mysql-utilities,下面是安装步骤:
tar -zxvf mysql-utilities-1.6.5.tar.gz
cd mysql-utilities-1.6.5
python ./setup.py build
python ./setup.py install
2
3
4
安装完成后,就可以使用命令查看 .frm 文件了:
mysqlfrm --diagnostic /usr/local/mysql/data/mall/account.frm
执行结果:
# WARNING: Cannot generate character set or collation names without the --server option.
# CAUTION: The diagnostic mode is a best-effort parse of the .frm file. As such, it may not identify all of the components of the table correctly. This is especially true for damaged files. It will also not read the default values for the columns and the resulting statement may not be syntactically correct.
# Reading .frm file for /usr/local/mysql/data/mall/account.frm:
# The .frm file is a TABLE.
# CREATE TABLE Statement:
CREATE TABLE `mall`.`account` (
`id` int(11) NOT NULL,
`name` varchar(150) DEFAULT NULL,
`balance` int(255) DEFAULT NULL,
PRIMARY KEY `PRIMARY` (`id`),
KEY `idx_balance` (`balance`)
) ENGINE=InnoDB;
#...done.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 四、存储引擎
查询 mysql 所有支持的存储引擎:
SHOW engines;
查询默认的存储引擎:
SHOW VARIABLES LIKE '%default_storage_engine%'
# 1、MyISAM
MyISAM 是 MySql 5.5 之前默认的存储引擎,是非聚集索引。
MyISAM 存储引擎由 MYD 和 MYI 组成。
创建一个表,并插入数据:
CREATE TABLE testmyisam ( id INT PRIMARY KEY ) ENGINE = myisam;
INSERT INTO testmyisam VALUES (1), (2), (3);
2
执行完后,去到数据库目录下可以看到生成了3个文件:.MYD、.MYI、.frm,其中 .MYI 存放的是索引(index),.MYD 存放的是数据(data),所以这种引擎的索引和数据是分开放的。
# (1) 表压缩
MyISAM 引擎是支持表压缩的。
表压缩的指令:
myisampack -b -f /usr/local/mysql/data/mall/testmyisam.MYI
执行这个命令后有可能会提示我们需要对表进行修复一下:
myisamchk -r -f /usr/local/mysql/data/mall/testmyisam.MYI
此时,这个文件就变成了 read only 状态,无法再往表里面新增数据了。
# (2) 适用场景
- 非事务型应用(数据仓库,报表,日志数据)
- 只读类应用
- 空间类应用(空间函数,坐标)
由于现在 innodb 越来越强大,myisam 已经停止维护
# 2、Innodb
MySQL 5.5 及以后版本默认存储引擎就是 Innodb
# (1) 特点
Innodb是一种事务性存储引擎- 完全支持事务得
ACID特性 Redo Log和Undo LogInnodb支持行级锁(并发程度更高)
查看创建数据库时使用的是独立表空间还是系统表空间:
SHOW variables like '%innodb_file_per_table%'
ON 表示使用的是独立表空间,即每个数据库存放的数据都是在一个独立的空间内,OFF 表示使用的是系统表空间,所有数据库的数据都存在 /data/ibdata1 (有可能是 ibdata2 等等) 内。
# (2) 适用场景
适合于大多数 OLTP 应用。
下面是 MyISAM 和 InnoDB 的对比:
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表所 | 表锁,即使操作一条记录也会所住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不会对其它行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |
# 3、CSV
# 特点
- 以
csv格式进行数据存储 - 所有列都不能为
null的 - 不支持索引(不适合大表,不适合在线处理)
- 可以对数据文件直接编辑(保存文本文件内容)
使用 CSV 引擎创建的表会生成3个文件:.CSM(保存表的元数据如状态和数量)、.CSV(文件存储内容)、.frm
创建一个表,并插入数据:
CREATE TABLE mycsv ( id INT NOT NULL, c1 VARCHAR ( 10 ) NOT NULL, c2 CHAR ( 10 ) NOT NULL ) ENGINE = csv;
INSERT INTO mycsv
VALUES
( 1, 'aaa', 'bbb' ),(
2,
'cccc',
'dddd'
);
2
3
4
5
6
7
8
此时,是可以直接编辑 .CSV 文件对数据做修改的,但是要注意保持和源数据一样的格式,编辑保存后,执行:
flush TABLES;
然后再查询可以看到刚才通过编辑文件修改的表数据。
# 4、Archive
# (1) 组成
- 以
zlib对表数据进行压缩,磁盘I/O更少 - 数据存储在 ARZ 为后缀的文件中
# (2) 特点:
- 只支持
insert和select操作 - 只允许在自增
ID列上加索引
创建表,并插入数据:
CREATE TABLE myarchive (
id INT auto_increment NOT NULL,
c1 VARCHAR ( 10 ),
c2 CHAR ( 10 ),
KEY ( id )) ENGINE = archive;
INSERT INTO myarchive ( c1, c2 ) VALUE ( 'aa', 'bb' ),( 'cc', 'dd' );
2
3
4
5
6
下面的语句是没法执行成功的:
CREATE INDEX idx_c1 ON myarchive (c1) # Too many keys specified; max 1 keys allowed
DELETE FROM myarchive WHERE id = 1 ; # Table storage engine for 'myarchive' doesn't have this option
UPDATE myarchive SET c1 = 'aaa' WHERE id = 1; #Table storage engine for 'myarchive' doesn't have this option
2
3
# 5、Memory
# (1) 特点
- 文件系统存储特点,也称
HEAP存储引擎,所以数据保存在内存中 - 支持
HASH索引和BTree索引,HASH索引在做等值查询的时候速度快,而BTree做范围查询效率高 - 所有字段都是固定长度
varchar(10) = char(10) - 不支持
Blog和Text等大字段 Memory存储引擎使用表级锁- 最大大小由
max_heap_table_size参数决定
查询 max_heap_table_size:
SHOW VARIABLES LIKE 'max_heap_table_size';
在我机器上,查到的是:16777216
下面这个语句无法创建成功:
CREATE TABLE mymemory ( id INT, c1 VARCHAR ( 10 ), c2 CHAR ( 10 ), c3 text ) ENGINE = memory; # The used table type doesn't support BLOB/TEXT columns
创建表并创建索引:
CREATE TABLE mymemory (
id INT,
c1 VARCHAR ( 10 ),
c2 CHAR ( 10 )) ENGINE = memory;
CREATE INDEX idx_c1 ON mymemory ( c1 );
CREATE INDEX idx_c2 USING BTREE ON mymemory ( c2 );
2
3
4
5
6
通过:
SHOW INDEX FROM mymemory;
可以看出默认创建的索引是 HASH 索引。
# (2) 临时表
使用 create temporary table 来创建临时表。
临时表分为两种,一种是系统使用的临时表,一种是用户创建的临时表。当系统创建表时超过了限制(例如大于最大容量)就会使用 Myisam 引擎来创建,未超过限制时才会使用 Memory 引擎。
# (3) 使用场景
- hash 索引用于查找或者是映射表(邮编和地区的对应表)
- 用于保存数据分析中产生的中间表
- 用于缓存周期性聚合数据的结果表
# 6、Ferderated
# (1) 特点
- 提供了访问远程
MySQL服务器上表的方法 - 本地不存储数据,数据全部放到远程服务器上
- 本地需要保存表结构和远程服务器的连接信息
# (2) 使用场景
偶尔的统计分析及手工查询(某些游戏行业)
在使用 SHOW ENGINES 查看的时候,发现 Ferderated 引擎默认是关闭的,需要开启:修改 /etc/my.cnf 在文件顶部加入:
[mysqld]
sql_mode="STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER"
federated
...
2
3
4
其中 federated 就是需要加的。
然后重启 mysql 服务即可:
/etc/inint.d/mysql stop
/etc/inint.d/mysql start
2
首先模拟创建一个本地库,这个库里面的表,不存放数据,是用来远程连接别的库的:
CREATE DATABASE local;
然后模拟创建一个远程库,这个库用来存放表和数据:
CREATE DATABASE remote;
进入 remote 库,创建表,并插入数据:
CREATE TABLE remote_fed (
id INT auto_increment NOT NULL,
c1 VARCHAR ( 10 ) NOT NULL DEFAULT '',
c2 CHAR ( 10 ) NOT NULL DEFAULT '',
PRIMARY KEY ( id )) ENGINE = INNODB;
INSERT INTO remote_fed ( c1, c2 ) VALUES ( 'aaa', 'bbb' ),( 'ccc', 'ddd' ),( 'eee', 'fff' );
2
3
4
5
6
接下来进入本地库 local,创建表:
CREATE TABLE `local_fed` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT,
`c1` VARCHAR ( 10 ) NOT NULL DEFAULT '',
`c2` CHAR ( 10 ) NOT NULL DEFAULT '',
PRIMARY KEY ( `id` )
) ENGINE = federated CONNECTION = 'mysql://root:123456@112.126.97.128:3306/remote/remote_fed'
2
3
4
5
6
接下来查询本地表:
SELECT * from local_fed
居然可以查到 remote 库中 remote_fed 表的内容,并且删除的话,remote 库 remote_fed 表的数据也会被删除。