# 线程的并发工具类
# 一、ForK-Join
# 1、分而治之
java下多线程的开发可以我们自己启用多线程、线程池,还可以使用 ForkJoin , ForkJoin 可以让我们不去了解 Thread , Runnable 等相关的知识,只需要遵循 ForkJoin 的开发模式即可。
ForkJoin 实际上使用了“分而治之”的思想,“分而治之”的策略是:对于一个规模为 n 的问题,若该问题可以容易地解决(比如说规模 n 较小)则直接解决,否则将其分解为 k 个规模较小的子问题,这些子问题互相独立且与原问题形式相同(子问题相互之间有联系就会变为动态规范算法),递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
# 2、归并排序
说到分而治之就不得不提到归并排序。归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列,即先使每个子序列有序,再使子序列段间有序。下面是一个归并排序的实现:
public class MergeSort {
private static int[] sort(int[] array) {
if (array.length <= MakeArray.THRESHOLD) {
return InsertionSort.sort(array);
} else {
// 切分数组,然后递归调用
int mid = array.length / 2;
int[] left = Arrays.copyOfRange(array, 0, mid);
int[] right = Arrays.copyOfRange(array, mid, array.length);
return merge(sort(left), sort(right));
}
}
/**
* 归并排序——将两段排序好的数组结合成一个排序数组
*
* @param left
* @param right
* @return
*/
private static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
// 左边数组已经取完,完全取右边数组的值即可
if (i >= left.length) {
result[index] = right[j++];
}
// 右边数组已经取完,完全取左边数组的值即可
else if (j >= right.length) {
result[index] = left[i++];
}
// 左边数组的元素值大于右边数组,取右边数组的值
else if (left[i] > right[j]) {
result[index] = right[j++];
}
// 右边数组的元素值大于左边数组,取左边数组的值
else {
result[index] = left[i++];
}
}
return result;
}
public static void main(String[] args) {
System.out.println("start calculating ...");
long start = System.currentTimeMillis();
MergeSort.sort(MakeArray.makeArray(40000000));
System.out.println("spend time: " + (System.currentTimeMillis() - start) + "ms");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
这里计算的是四千万长度的一个随机数组,执行结果:
start calculating ...
spend time: 5966ms
2
其中使用到的插入排序:
public class InsertionSort {
public static int[] sort(int[] array) {
if (array.length == 0) {
return array;
}
// 当前待排序数据,该元素之前的元素均已被排序过
int currentValue;
for (int i = 0; i < array.length - 1; i++) {
// 已被排序数据的索引
int preIndex = i;
currentValue = array[preIndex + 1];
// 在已被排序过数据中倒序寻找合适的位置,如果当前待排序数据比比较的元素要小,将比较的元素元素后移一位
while (preIndex >= 0 && currentValue < array[preIndex]) {
// 将当前元素后移一位
array[preIndex + 1] = array[preIndex];
preIndex--;
}
// while循环结束时,说明已经找到了当前待排序数据的合适位置,插入
array[preIndex + 1] = currentValue;
}
return array;
}
public static void main(String[] args) {
System.out.println("start calculating ...");
long start = System.currentTimeMillis();
InsertionSort.sort(MakeArray.makeArray(400000));
System.out.println("spend time: " + (System.currentTimeMillis() - start) + "ms");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
执行结果:
start calculating ...
spend time: 12795ms
2
这里计算的是一个四十万长度的数组,花费的时间还是挺长的。
生成数组的工具类:
public class MakeArray {
/**
* 默认数组长度
*/
public static final int ARRAY_LENGTH = 10000;
/**
* 拆分阈值
*/
public final static int THRESHOLD = 47;
public static int[] makeArray() {
return makeArray(ARRAY_LENGTH);
}
public static int[] makeArray(int length) {
Random r = new Random();
int[] result = new int[length];
for (int i = 0; i < length; i++) {
// 用随机数填充数组
result[i] = r.nextInt(length * 3);
}
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 3、ForK-Join 原理
在必要的情况下,将一个大人物进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算结果进行汇总(join)。
# 4、ForK-Join 使用
首先创建一个 ForkJoin 任务。它提供在任务中执行 fork 和 join 的操作机制,通常我们不直接继承 ForkJoinTask 类,只需要直接继承其子类:
- RecursiveTask
用于有返回值的任务
- RecursiveAction
用于没有返回结果的任务
ForkJoinTask 任务类:
通过
ForkJoinPool来执行,使用submit()或invoke()提交,两者的区别是:invoke()是同步执行,调用之后需要等待任务完成,才能执行后面的代码;而submit()是异步执行。通过
join()和get()方法当任务完成的时候返回计算结果,他们区别是get()方法可以捕获InterruptedException和ExecutionException异常。通过
compute()方法用来计算,这是一个抽象方法,需要我们来实现,也就是我们自己的计算逻辑。我们在设计时,应当首先判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须再分割成两个子任务,每个子任务在调用invokeAll()方法时,又会进入compute()方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join()方法会等待子任务执行完并得到其结果。
下面通过三个例子演示:
第一个例子演示了 RecursiveTask 的使用,并且调用了同步的提交方法:
public class SumArray {
private static class SumTask extends RecursiveTask<Integer> {
/**
* 阈值
*/
private final static int THRESHOLD = MakeArray.ARRAY_LENGTH / 10;
private int[] src;
private int fromIndex;
private int toIndex;
public SumTask(int[] src, int fromIndex, int toIndex) {
this.src = src;
this.fromIndex = fromIndex;
this.toIndex = toIndex;
}
@Override
protected Integer compute() {
// 判断任务的大小是否合适
if (toIndex - fromIndex < THRESHOLD) {
int count = 0;
for (int i = fromIndex; i <= toIndex; i++) {
SleepTool.ms(1);
count = count + src[i];
}
return count;
}
// 不满足阈值则继续拆分
else {
int mid = (fromIndex + toIndex) / 2;
SumTask left = new SumTask(src, fromIndex, mid);
SumTask right = new SumTask(src, mid + 1, toIndex);
invokeAll(left, right);
return left.join() + right.join();
}
}
}
public static void main(String[] args) {
int[] src = MakeArray.makeArray(10000);
// 池实例
ForkJoinPool pool = new ForkJoinPool();
// Task实例
SumTask sumTask = new SumTask(src, 0, src.length - 1);
long start = System.currentTimeMillis();
pool.invoke(sumTask);
System.out.println("The count is " + sumTask.join() + ", spend time: " + (System.currentTimeMillis() - start) + "ms");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
这是对数组进行求和的应用,当拆分到足够小的数组时,进行求和,最终汇总。
invokeAll() 是一个阻塞方法,必须等待所有任务执行完毕,它有3个重载,接收的参数分别是:两个 ForkJoinTask 对象、 ForkJoinTask 数组、 ForkJoinTask 集合。
执行结果:
The count is 150032459, spend time: 2262ms
用到的生成数组的工具里比较简单,在这里有说明:插入排序
第二个例子演示了 RecursiveAction 的使用,并且调用了异步的提交方法:
public class FindDirsFiles extends RecursiveAction {
private File path;
public FindDirsFiles(File path) {
this.path = path;
}
@Override
protected void compute() {
List<FindDirsFiles> subTasks = new ArrayList<>();
File[] files = path.listFiles();
if (files != null) {
for (File file : files) {
if (file.isDirectory()) {
// 对每个子目录都新建一个子任务
subTasks.add(new FindDirsFiles(file));
} else {
// 遇到文件则检查
if (file.getAbsolutePath().endsWith("txt")) {
System.out.println("文件:" + file.getAbsolutePath());
}
}
}
if (!subTasks.isEmpty()) {
// 在当前的 ForkJoinPool 上调度所有的子任务
// invokeAll 会将所有任务进行执行,并将执行结果封装到任务中进行返回
invokeAll(subTasks);
}
}
}
public static void main(String[] args) {
try {
ForkJoinPool pool = new ForkJoinPool();
FindDirsFiles task = new FindDirsFiles(new File("E:/Document"));
// 异步提交
pool.execute(task);
// 主线程做自己的业务工作
System.out.println("main thread is Running ...");
Thread.sleep(1);
int sum = 0;
for (int i = 0; i < 100; i++) {
sum = sum + i;
}
System.out.println("main thread finished count, sum: " + sum);
// 这是一个阻塞方法
task.join();
System.out.println("task end");
} catch (Exception e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
这是对电脑硬盘上的 .txt 文件进行检索并输出。执行结果:
main thread is Running ...
main thread finished count, sum: 4950
文件:E:\Document\新建文本文档.txt
文件:E:\Document\2\新建文本文档2.txt
文件:E:\Document\2\新建文本文档3.txt
文件:E:\Document\3\新建文本文档4.txt
文件:E:\Document\3\新建文本文档5.txt
文件:E:\Document\3\新建文本文档6.txt
task end
2
3
4
5
6
7
8
9
第三个例子是使用 RecursiveTask 来实现的归并排序:
public class ForkJoinSort {
private static class SortTask extends RecursiveTask<int[]> {
/**
* 阈值
*/
private final static int THRESHOLD = MakeArray.ARRAY_LENGTH / 10;
private int[] src;
public SortTask(int[] src) {
this.src = src;
}
@Override
protected int[] compute() {
if (src.length <= THRESHOLD) {
return InsertionSort.sort(src);
} else {
// 切分数组,然后递归调用
int mid = src.length / 2;
int[] left = Arrays.copyOfRange(src, 0, mid);
int[] right = Arrays.copyOfRange(src, mid, src.length);
SortTask leftTask = new SortTask(left);
SortTask rightTask = new SortTask(right);
invokeAll(leftTask, rightTask);
int[] leftResult = leftTask.join();
int[] rightResult = rightTask.join();
return merge(leftResult, rightResult);
}
}
}
/**
* 归并排序——将两段排序好的数组结合成一个排序数组
*
* @param left
* @param right
* @return
*/
private static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
// 左边数组已经取完,完全取右边数组的值即可
if (i >= left.length) {
result[index] = right[j++];
}
// 右边数组已经取完,完全取左边数组的值即可
else if (j >= right.length) {
result[index] = left[i++];
}
// 左边数组的元素值大于右边数组,取右边数组的值
else if (left[i] > right[j]) {
result[index] = right[j++];
}
// 右边数组的元素值大于左边数组,取左边数组的值
else {
result[index] = left[i++];
}
}
return result;
}
public static void main(String[] args) {
int[] src = MakeArray.makeArray(40000000);
// 池实例
ForkJoinPool pool = new ForkJoinPool();
// Task实例
SortTask sortTask = new SortTask(src);
long start = System.currentTimeMillis();
pool.invoke(sortTask);
System.out.println("spend time: " + (System.currentTimeMillis() - start) + "ms");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
运行结果:
spend time: 2316ms
当拆分到阈值之内的,时候调用了上面写到的插入排序。
可以看出,使用 ForkJoin 实现的归并排序,要比原生的归并排序性能还是要高一些的。
# 5、工作密取
即当前线程的 Task 已经全被执行完毕,则自动取到其他线程的 Task 池中取出 Task 继续执行。
ForkJoinPool 中维护着多个线程(一般为CPU的核数)在不断地执行 Task,每个线程除了执行自己职务内的 Task 之外,还会根据自己工作线程的闲置情况去获取其他繁忙的工作线程的 Task ,如此一来就能能够减少线程阻塞或是闲置的时间,提高CPU利用率。
下面是一个例子:
public class SecretWorkFetch {
private static class Work implements Runnable {
private static Object object = new Object();
private static int COUNT = 0;
public final int id;
private long putThread;
public Work() {
synchronized (object) {
id = COUNT++;
}
}
@Override
public void run() {
if (Thread.currentThread().getId() != putThread) {
System.out.println("!!!!!! put thread is " + putThread + ", but " +
Thread.currentThread().getId() + "finished the job");
} else {
System.out.println("put thread is " + putThread + ", and " +
Thread.currentThread().getId() + "finished the job");
}
}
public long getPutThread() {
return putThread;
}
public void setPutThread(long putThread) {
this.putThread = putThread;
}
}
public static Work generateWork() {
return new Work();
}
private static class ConsumerAndProducer implements Runnable {
private Random random = new Random();
private final LinkedBlockingDeque<Work> deque;
private final LinkedBlockingDeque<Work> other;
public ConsumerAndProducer(LinkedBlockingDeque<Work> deque, LinkedBlockingDeque<Work> other) {
this.deque = deque;
this.other = other;
}
@Override
public void run() {
while (!Thread.interrupted()) {
try {
Thread.sleep(1000);
// 一定概率创建5以内的 work 放入 deque
if (random.nextBoolean()) {
int count = random.nextInt(5);
for (int i = 0; i < count; i++) {
Work w = generateWork();
w.setPutThread(Thread.currentThread().getId());
deque.putLast(w);
}
}
// 如果 deque 队列执行完了就会从 other 中获取任务执行
if (deque.isEmpty()) {
if (!other.isEmpty()) {
System.out.println("take from other ...");
other.takeLast().run();
}
} else {
deque.takeFirst().run();
}
} catch (InterruptedException e) {
}
}
}
}
public static void main(String[] args) {
LinkedBlockingDeque<Work> work1 = new LinkedBlockingDeque<>();
LinkedBlockingDeque<Work> work2 = new LinkedBlockingDeque<>();
new Thread(new ConsumerAndProducer(work1, work2)).start();
new Thread(new ConsumerAndProducer(work1, work2)).start();
new Thread(new ConsumerAndProducer(work2, work1)).start();
new Thread(new ConsumerAndProducer(work2, work1)).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
一共有4个线程,其中2个线程将 work1 作为自己的主任务, 另外2个线程将 work2 作为自己的主任务,4个线程并行执行,当前2个线程执行完 work1 中的任务时,就会去 work2 中拿任务执行,后面2个线程当执行完 work2 中的任务时,也会去 work1 中拿任务执行。
执行结果:
put thread is 13, and 13finished the job
put thread is 15, and 15finished the job
take from other ...
!!!!!! put thread is 14, but 12finished the job
!!!!!! put thread is 15, but 14finished the job
take from other ...
!!!!!! put thread is 14, but 13finished the job
put thread is 15, and 15finished the job
take from other ...
!!!!!! put thread is 14, but 12finished the job
!!!!!! put thread is 15, but 14finished the job
put thread is 13, and 13finished the job
...
2
3
4
5
6
7
8
9
10
11
12
13
# 二、CountDownLatch
CountDownLatch 这个类能够使一个线程等待其他线程完成各自的工作后再执行。例如,应用程序的主线程希望在负责启动框架服务的线程已经启动所有的框架服务之后再执行。
CountDownLatch 是通过一个计数器来实现的,计数器的初始值为初始任务的数量。每当完成了一个任务后,计数器的值就会减1,(调用 countDown() 方法)。当计数器值到达0时,它表示已经完成了所有的任务,然后在调用 CountDownLatch 的 等待方法 await() 的线程就可以恢复执行任务。
下面是一个使用列子:
public class UseCountDownLatch {
private static CountDownLatch latch = new CountDownLatch(6);
/**
* 初始化线程
*/
private static class InitThread implements Runnable {
public void run() {
System.out.println("Thread_" + Thread.currentThread().getId() + " ready init work ...");
latch.countDown();
for (int i = 0; i < 2; i++) {
System.out.println("Thread_" + Thread.currentThread().getId() + " continue do its work ...");
}
}
}
/**
* 业务线程等待 latch 的计数器为0完成
*/
private static class BusinessThread implements Runnable {
public void run() {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
for (int i = 0; i < 3; i++) {
System.out.println("BusinessThread_" + Thread.currentThread().getId() + " do business ---");
}
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
SleepTool.ms(1);
System.out.println("Thread_" + Thread.currentThread().getId() + " ready init work step 1st ...");
latch.countDown();
System.out.println("begin step 2nd ...");
SleepTool.ms(1);
System.out.println("Thread_" + Thread.currentThread().getId() + " ready init work step 2nd ...");
latch.countDown();
}).start();
new Thread(new BusinessThread()).start();
for (int i = 0; i < 4; i++) {
Thread thread = new Thread(new InitThread());
thread.start();
}
latch.await();
System.out.println("main do its work ...");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
初始化了6个需要扣除的计数点,4个初始化线程每个线程执行完毕一个就会扣除一个计数点,主线程还会扣除2个计数点,等待计数点扣完主线程和业务线程继续执行。
Thread_12 ready init work step 1st ...
begin step 2nd ...
Thread_12 ready init work step 2nd ...
Thread_14 ready init work ...
Thread_14 continue do its work ...
Thread_14 continue do its work ...
Thread_15 ready init work ...
Thread_15 continue do its work ...
Thread_15 continue do its work ...
Thread_16 ready init work ...
Thread_16 continue do its work ...
Thread_16 continue do its work ...
Thread_17 ready init work ...
Thread_17 continue do its work ...
Thread_17 continue do its work ...
BusinessThread_13 do business ---
BusinessThread_13 do business ---
BusinessThread_13 do business ---
main do its work ...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 三、CyclicBarrier
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用 await() 方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
CyclicBarrier 还提供一个更高级的构造函数 CyclicBarrie(r int parties,Runnable barrierAction),用于在线程到达屏障时,优先执行 barrierAction ,方便处理更复杂的业务场景。
CyclicBarrier 可以用于多线程计算数据,最后合并计算结果的场景。
示例:
public class UseCyclicBarrier {
private static CyclicBarrier BARRIER = new CyclicBarrier(4, new CollectThread());
// 存放子线程工作结果的容器
private static ConcurrentHashMap<String, Long> RESULT_MAP = new ConcurrentHashMap<>();
public static void main(String[] args) {
for (int i = 0; i < 4; i++) {
Thread thread = new Thread(new SubThread());
thread.start();
}
}
/**
* 汇总的任务
*/
private static class CollectThread implements Runnable {
@Override
public void run() {
StringBuilder result = new StringBuilder();
for (Map.Entry<String, Long> workResult : RESULT_MAP.entrySet()) {
result.append("[").append(workResult.getValue()).append("]");
}
System.out.println("the result = " + result);
System.out.println("CollectThread has done its job");
}
}
/**
* 相互等待的子线程
*/
private static class SubThread implements Runnable {
@Override
public void run() {
long id = Thread.currentThread().getId();
RESULT_MAP.put(Thread.currentThread().getId() + "", id);
try {
Thread.sleep(1000 + id);
System.out.println("Thread_" + id + " is doing first job");
BARRIER.await();
Thread.sleep(1000 + id);
System.out.println("Thread_" + id + " is doing second job");
BARRIER.await();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
执行结果:
Thread_12 is doing first job
Thread_13 is doing first job
Thread_14 is doing first job
Thread_15 is doing first job
the result = [12][13][14][15]
CollectThread has done its job
Thread_12 is doing second job
Thread_13 is doing second job
Thread_14 is doing second job
Thread_15 is doing second job
the result = [12][13][14][15]
CollectThread has done its job
2
3
4
5
6
7
8
9
10
11
12
在这个例子中,SubThread 中一共使用了两次 await() 方法,每次调用 await() 方法都会等待所有4个线程都执行完后会执行 CollectThread 中的逻辑。
# CountDownLatch 和 CyclicBarrier 辨析
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以反复使用。CountDownLatch的await()一般阻塞工作线程,所有的进行预备工作的线程执行countDown()方法进行扣减,而CyclicBarrier通过工作线程调用await()从而自行阻塞,直到所有工作线程达到指定屏障,再大家一起往下走。在控制多个线程同时运行上,
CountDownLatch可以不限线程数量,而CyclicBarrier是固定线程数。CyclicBarrier还可以提供一个barrierAction,合并多线程计算结果。
# 四、Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。Semaphore 可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是 IO 密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用 Semaphore 来做流量控制。Semaphore 的构造方法 Semaphore(int permits)接受一个整型的数字,表示可用的许可证数量。Semaphore 的用法也很简单,首先线程使用 Semaphore 的 acquire() 方法获取一个许可证,使用完之后调用 release() 方法归还许可证。还可以用 tryAcquire() 方法尝试获取许可证。
Semaphore 还提供一些其他方法,具体如下。
- int availablePermits()
返回此信号量中当前可用的许可证数。
- int getQueueLength()
返回正在等待获取许可证的线程数。
- boolean hasQueuedThreads()
是否有线程正在等待获取许可证。
- void reducePermits(int reduction)
减少 reduction 个许可证,是个 protected 方法。
- Collection getQueuedThreads()
返回所有等待获取许可证的线程集合,是个 protected 方法。
下面是使用 Semaphore 实现的数据库连接池示例:
public class DBPoolSemaphore {
private final static int POOL_SIZE = 10;
/**
* 可用连接数
*/
private final Semaphore useful;
/**
* 已用连接数
*/
private final Semaphore useless;
/**
* 存放数据库连接的容器
*/
private static LinkedList<Connection> pool = new LinkedList<>();
/**
* 初始化池
*/
static {
for (int i = 0; i < POOL_SIZE; i++) {
pool.addLast(SqlConnectImpl.fetchConnection());
}
}
public DBPoolSemaphore() {
useful = new Semaphore(10);
useless = new Semaphore(0);
}
/**
* 归还连接
*
* @param connection
* @throws InterruptedException
*/
public void returnConnect(Connection connection) throws InterruptedException {
if (connection != null) {
useless.acquire();
synchronized (pool) {
pool.addLast(connection);
}
useful.release();
System.out.println("当前有" + useful.getQueueLength() + "个线程等待数据库连接,可用连接数:"
+ useful.availablePermits());
}
}
/**
* 从连接池获取连接
*
* @return
* @throws InterruptedException
*/
public Connection takeConnect() throws InterruptedException {
// 这个方法会阻塞,直到获取到就往下执行
useful.acquire();
Connection connection;
synchronized (pool) {
connection = pool.removeFirst();
}
useless.release();
return connection;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
这里定义了两个 Semaphore ,一个用于管控可用连接数,一个用于管控已用连接数。
测试类:
public class AppTest {
private static DBPoolSemaphore dbPool = new DBPoolSemaphore();
private static class BusinessThread extends Thread {
@Override
public void run() {
// 让每个线程持有连接的时间不一样
Random r = new Random();
long start = System.currentTimeMillis();
try {
Connection connect = dbPool.takeConnect();
System.out.println("Thread_" + Thread.currentThread().getId()
+ "_获取数据库连接共耗时:" + (System.currentTimeMillis() - start) + "ms.");
// 模拟业务操作,线程持有连接查询数据
SleepTool.ms(100 + r.nextInt(100));
System.out.println("查询数据完成,归还连接!");
dbPool.returnConnect(connect);
} catch (InterruptedException e) {
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 50; i++) {
Thread thread = new BusinessThread();
thread.start();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
执行结果:
Thread_15_获取数据库连接共耗时:0ms.
Thread_20_获取数据库连接共耗时:0ms.
Thread_19_获取数据库连接共耗时:0ms.
Thread_21_获取数据库连接共耗时:0ms.
Thread_12_获取数据库连接共耗时:0ms.
Thread_16_获取数据库连接共耗时:0ms.
Thread_17_获取数据库连接共耗时:0ms.
Thread_13_获取数据库连接共耗时:0ms.
Thread_18_获取数据库连接共耗时:0ms.
Thread_14_获取数据库连接共耗时:0ms.
查询数据完成,归还连接!
当前有40个线程等待数据库连接,可用连接数:1
Thread_22_获取数据库连接共耗时:111ms.
查询数据完成,归还连接!
查询数据完成,归还连接!
当前有38个线程等待数据库连接,可用连接数:1
...
当前有0个线程等待数据库连接,可用连接数:7
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:8
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:9
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:10
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
在上面这个例子中,因为定义了两个 Semaphore,将已用连接数也作为资源储存起来,如果想只用一个 Semaphore 来保存可用连接数的话,那么就必须确保在 Connection 进行获取和归还的时候是同一个 Connection,否则会出问题,例如:
public class DBPoolNoUseless {
private final static int POOL_SIZE = 10;
/**
* 可用连接数
*/
private final Semaphore useful;
/**
* 存放数据库连接的容器
*/
private static LinkedList<Connection> pool = new LinkedList<>();
/**
* 初始化池
*/
static {
for (int i = 0; i < POOL_SIZE; i++) {
pool.addLast(SqlConnectImpl.fetchConnection());
}
}
public DBPoolNoUseless() {
useful = new Semaphore(10);
}
/**
* 归还连接
*
* @param connection
* @throws InterruptedException
*/
public void returnConnect(Connection connection) throws InterruptedException {
if (connection != null) {
synchronized (pool) {
pool.addLast(connection);
}
useful.release();
System.out.println("当前有" + useful.getQueueLength() + "个线程等待数据库连接,可用连接数:"
+ useful.availablePermits());
}
}
/**
* 从连接池获取连接
*
* @return
* @throws InterruptedException
*/
public Connection takeConnect() throws InterruptedException {
// 这个方法会阻塞,直到获取到就往下执行
useful.acquire();
Connection connection;
synchronized (pool) {
connection = pool.removeFirst();
}
return connection;
}
private static DBPoolNoUseless dbPoolNoUseless = new DBPoolNoUseless();
private static class BusinessThread extends Thread {
@Override
public void run() {
Random r = new Random();
long start = System.currentTimeMillis();
try {
System.out.println("Thread_" + Thread.currentThread().getId()
+ "_获取数据库连接共耗时:" + (System.currentTimeMillis() - start) + "ms.");
SleepTool.ms(100 + r.nextInt(100));
System.out.println("查询数据完成,归还连接!");
dbPoolNoUseless.returnConnect(new SqlConnectImpl());
} catch (InterruptedException e) {
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 50; i++) {
Thread thread = new BusinessThread();
thread.start();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
执行结果:
Thread_17_获取数据库连接共耗时:0ms.
Thread_15_获取数据库连接共耗时:0ms.
Thread_24_获取数据库连接共耗时:0ms.
Thread_16_获取数据库连接共耗时:0ms.
Thread_13_获取数据库连接共耗时:0ms.
Thread_19_获取数据库连接共耗时:0ms.
Thread_14_获取数据库连接共耗时:0ms.
Thread_18_获取数据库连接共耗时:0ms.
Thread_12_获取数据库连接共耗时:0ms.
Thread_23_获取数据库连接共耗时:0ms.
Thread_21_获取数据库连接共耗时:0ms.
Thread_25_获取数据库连接共耗时:0ms.
Thread_22_获取数据库连接共耗时:0ms.
Thread_20_获取数据库连接共耗时:0ms.
Thread_28_获取数据库连接共耗时:0ms.
...
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:55
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:56
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:57
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:58
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:59
查询数据完成,归还连接!
当前有0个线程等待数据库连接,可用连接数:60
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
在这个例子中,使用了一个 Semaphore,并且在归还连接的时候是直接 new SqlConnectImpl() 所以运行结果就完全不受最大数10个连接的限制了,出现了错误。
# 五、Exchange
Exchanger(交换者)是一个用于线程间协作的工具类。 Exchanger 用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过 exchange() 方法交换数据,如果第一个线程先执行 exchange() 方法,它会一直等待第二个线程也执行 exchange() 方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
示例:
public class UseExchange {
private static final Exchanger<Set<String>> exchange = new Exchanger<>();
public static void main(String[] args) {
new Thread(() -> {
Set<String> setA = new HashSet<>();
try {
setA.add("a1");
setA.add("a2");
setA.add("a3");
setA = exchange.exchange(setA);
System.out.println("setA的数据:" + setA);
} catch (InterruptedException e) {
}
}).start();
new Thread(() -> {
Set<String> setB = new HashSet<>();
try {
setB.add("b1");
setB.add("b2");
setB.add("b3");
setB = exchange.exchange(setB);
System.out.println("setB的数据:" + setB);
} catch (InterruptedException e) {
}
}).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
执行结果:
setA的数据:[b2, b3, b1]
setB的数据:[a1, a2, a3]
2
# 六、Callable、Future 和 FutureTask
Runnable 是一个接口,在它里面只声明了一个 run() 方法,由于 run() 方法返回值为 void 类型,所以在执行完任务之后无法返回任何结果。
Callable 位于 java.util.concurrent 包下,它也是一个接口,在它里面也只声明了一个方法,只不过这个方法叫做 call() ,这是一个泛型接口,call() 函数返回的类型就是传递进来的 V 泛型的类型。
Future 就是对于具体的 Runnable 或者 Callable 任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过 get() 方法获取执行结果,该方法会阻塞直到任务返回结果。
因为 Future 只是一个接口,所以是无法直接用来创建对象使用的,而 FutureTask 实现了 RunnableFuture 接口,其中 RunnableFuture 继承了 Runnable 接口和 Future 接口,而 FutureTask 实现了 RunnableFuture 接口。所以它既可以作为 Runnable 被线程执行,又可以作为 Future 得到 Callable 的返回值。
它们之间的关系见下图:
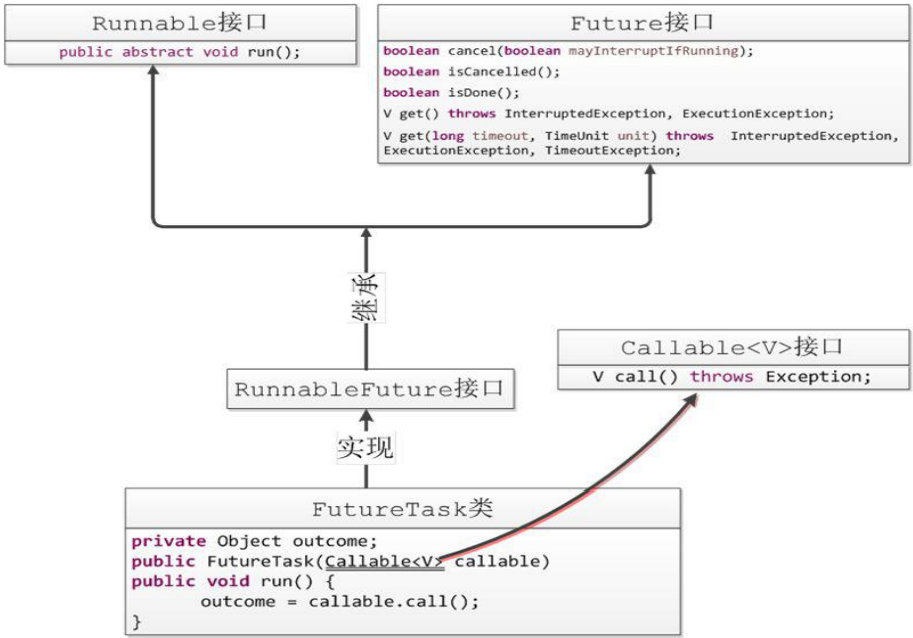
因此通过一个线程运行 Callable,但是 Thread 不支持构造方法中传递 Callable 的实例,所以需要通过 FutureTask 把一个 Callable 包装成 Runnable,然后再通过这个 FutureTask 拿到 Callable 运行后的返回值。
FutureTask 的构造方法有两个: FutureTask(Callable<V>) 以及 FutureTask(Runnable, V)。
示例:
public class UseFuture {
/**
* 实现 Callable 接口,允许有返回值
*/
private static class UseCallable implements Callable<Integer> {
private int sum;
@Override
public Integer call() {
System.out.println("Callable子线程开始计算!");
for (int i = 0; i < 5000; i++) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("Callable子线程计算任务中断!");
return null;
}
sum = sum + i;
System.out.println("sum: " + sum);
}
System.out.println("Callable子线程计算结束!结果为:" + sum);
return sum;
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
UseCallable useCallable = new UseCallable();
// 包装
FutureTask<Integer> futureTask = new FutureTask<>(useCallable);
Random r = new Random();
new Thread(futureTask).start();
Thread.sleep(1);
if (r.nextInt(100) > 50) {
// get() 方法会阻塞
System.out.println("get UseCallable result: " + futureTask.get());
} else {
System.out.println("cancel ...");
futureTask.cancel(true);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
执行结果:
Callable子线程开始计算!
sum: 0
sum: 1
sum: 3
...
sum: 12492501
sum: 12497500
Callable子线程计算结束!结果为:12497500
get UseCallable result: 12497500
2
3
4
5
6
7
8
9
有一半的概率会调用 futureTask.cancel(true) 而中断线程。
← 线程之间的共享和协作 原子操作CAS →