# 深入理解JVM内存区域
# 一、为什么要了解虚拟机
JVM 不单单只支持 Java 语言,也支持其他语言(Scala、Kotlin、Groovy 等等)
区块链 2.0--以太坊(比特币是区块链 1.0) 中提供了 EVM 的虚拟机,它的实现和 JVM 类似,基于栈、生成脚本编译成字节码来执行。知识通用。(理论大于实际)
# 二、虚拟机历史
# 解释执行和编译执行(针对字节码的执行)
解释执行就是边翻译为机器码边执行、即时编译(编译执行)就是先将一个方法中的所有字节码全部编译成机器码之后再执行。
Hotspot VM(sun)
采用的是先解释执行,到了一定时机后将热点代码(多次执行、循环等)再翻译成机器码
热点代码探测技术(通过执行计数器找到最有编译价值的代码,如果代码用得非常频繁,就会把这些代码编译成本地代码)。是目前应用最广泛的虚拟机。
JRockit VM(BEA)
采取的方法是在执行 class 时直接编译为机器码(Java 程序启动速度会比较慢)
J9 VM(IBM)
和 Hotspot 比较接近,主要是用在 IBM 产品(IBM WebSphere 和 IBM 的 AIX 平台上),华为有的项目用的 J9。
Google Android Dalivk VM(谷歌)
使用的寄存器架构,执行 dex(Dalvik Executable)通过 class 转化而来。
# 三、未来的 Java 技术
# 1、模块化
OSGI(动态化、模块化),应用层面就是微服务,互联网的发展方向
# 2、混合语言
多个语言都可以运行在 JVM 中,google 的 Kotlin 成为了 Android 的官方语言。Scala(Kafka)
# 3、多核并行
CPU 从高频次转变为多核心,多核时代。JDK1.7 引入了 Fork/Join,JDK1.8 提出 lambda 表达式(函数式编程天生适合并行运行)
# 4、丰富语法
JDK5 提出自动装箱、泛型(并发编程讲到)、动态注解等语法。JDK7 二进制原生支持。try-catch-finally 至 try-with-resource
# 5、64位
虽然同样的程序 64 位内存消耗比 32 位要多一点,但是支持内存大,所以虚拟机都会完全过渡到 64 位,32 位的 JVM 有 4G 的堆大小限制。
# 6、更强的垃圾回收器
现在主流 CMS、G1。JDK11 中的 –ZGC(暂停时间不超过 10 毫秒,且不会随着堆的增加而增加,TB 级别的堆回收))。
有色指针、加载屏障。JDK12 支持并发类卸载,进一步缩短暂停时间 JDK13(计划于 2019 年 9 月)将最大堆大小从 4TB 增加到 16TB
# 四、Java SE 体系架构
- JavaSE
Java 平台标准版,为 Java EE 和 Java ME 提供了基础。
- JDK
Java 开发工具包,JDK 是 JRE 的超集,包含 JRE 中的所有内容,以及开发程序所需的编译器和调试程序等工具。
- JRE
Java SE 运行时环境 ,提供库、Java 虚拟机和其他组件来运行用 Java 编程语言编写的程序。主要类库,包括:程序部署发布、用户界面工具类、继承库、其他基础库,语言和工具基础库
- JVM
java 虚拟机,负责 Java SE 平台的硬件和操作系统无关性、编译执行代码(字节码)和平台安全性
# 五、运行时数据区域
这个是抽象概念,内部实现依赖寄存器、高速缓存、主内存(具体要分析 JVM 源码的 C++ 语言实现)
JVM 在运行过程中会把它所管理的内存划分成若干不同的数据区域。
线程私有:程序计数器、虚拟机栈、本地方法栈
线程共享:堆、方法区
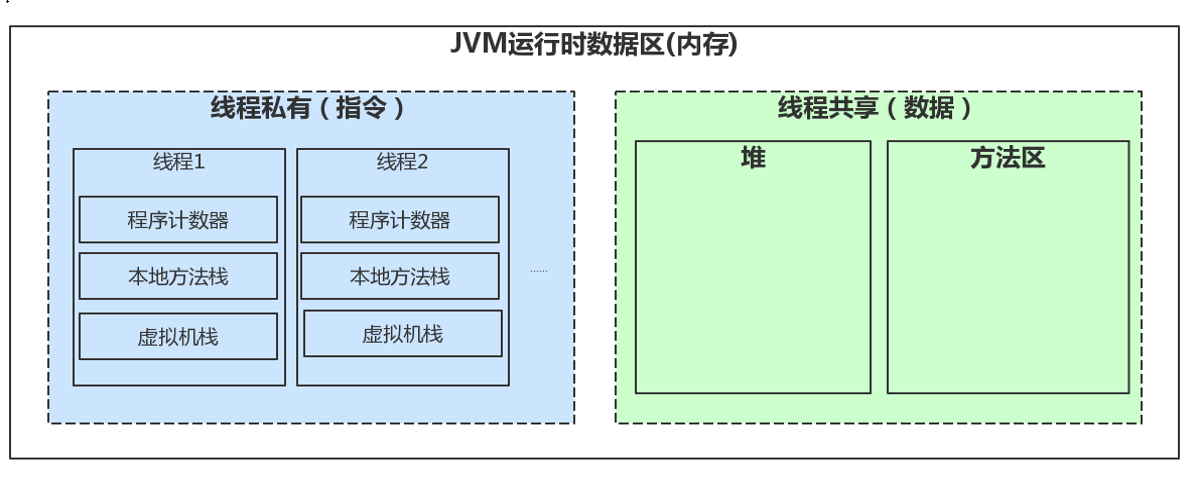
线程私有是存储指令的,线程共享是存储数据的。
计算机的运行 = 指令 + 数据,指令用于执行方法的,数据用于存放数据和对象的。
# 1、线程私有的区域
# (1) 程序计数器
程序执行的计数器。占用较小的内存空间,当前线程执行的字节码的行号指示器;各线程之间独立存储,互不影响。
如果线程正在执行的是一个 Java 方法,则指向的是当前线程执行的代字节码行数。
如果正在执行的是 Natvie 方法,这个计数器值则为空(Undefined)
此内存区域是唯一一个不会出现 OutOfMemoryError 情况的区域。
# 为什么需要程序计数器
因为 Java 是多线程的,当需要线程切换的时候需要确保多线程情况下程序能够正确执行,需要记录正在执行代码字节的行数。
# (2) 虚拟机栈
存储当前线程运行方法所需要的数据、指令和返回地址。
栈数据结构的特点和 Java 中方法中调用方法的特性一致。
public class StackFilo {
public static void main(String[] args) {
// a() -> b() -> c()
a();
}
public static void a() {
System.out.println("A开始");
// 此处省略100行代码
// 调用 b() 方法
b();
System.out.println("A结束");
}
public static void b() {
System.out.println("B开始");
// 此处省略100行代码
// 调用 c() 方法
c();
System.out.println("B结束");
}
public static void c() {
System.out.println("C开始");
// 此处省略100行代码
System.out.println("C结束");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
上面代码依次入栈的方法为 a() -> b() -> c(),出栈的顺序为 c() -> b() -> a()
当线程请求的栈深度大于虚拟机所允许的深度时,会抛出 StackOverflowError 异常。
当 JVM 动态扩展时无法申请到足够的内存时,会抛出 OutOfMemoryError 异常。
虚拟机栈 是每个线程私有的,线程在运行时,在执行每个方法的时候都会打包成一个栈帧,存储了局部变量表,操作数栈,动态链接,方法出口等信息,然后放入栈。每个时刻正在执行的当前方法就是虚拟机栈顶的栈桢。方法的执行就对应着栈帧在虚拟机栈中入栈和出栈的过程。
虚拟机栈 的大小缺省为 1M,可用参数 –Xss 调整大小,例如 -Xss256k。
在编译程序代码的时候,栈帧中需要多大的局部变量表,多深的操作数栈都已经完全确定了,并且写入到方法表的 Code 属性之中,因此一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。
通过 javap -v xxx.class > xxx.txt 可以将 class 文件信息转化为一个文本信息,在文本信息中包含着字节码的信息。
在字节码的方法中会包含一个 Code 属性的数据,下面举例介绍里面的几种语法:
例如 Java 代码如下:
public void use(int money) {
money = money - 100;
}
2
3
通过上述指令执行后生成的文件中 use() 方法对应的内容如下:
public void use(int);
descriptor: (I)V
flags: ACC_PUBLIC
Code:
stack=2, locals=2, args_size=2
0: iload_1
1: bipush 100
3: isub
4: istore_1
5: return
LineNumberTable:
line 28: 0
line 29: 5
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this Lcom/jerry/ch1/JavaStack;
0 6 1 money I
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在 Code 属性中有一些指令,指令左边的数字代表的就是指令的行号。因为虚拟机在执行指令的过程中可能还在做一些其它的工作,所以行号没有连续。
| 行号 | 指令 | 含义 |
|---|---|---|
| 0 | iload_1 | 将下标为1的 int 型局部变量进栈 |
| 1 | bipush | 将一个 byte 型常量(100)值推送至栈顶 |
| 3 | isub | 栈顶两个 int 行数值相减(后入栈的 - 前入栈的),并且结果进栈 |
| 4 | istore_1 | 将栈顶 int 型数值存入第2个局部变量 |
- 局部变量表(LocalVariableTable)
顾名思义就是局部变量的表,用于存放我们的局部变量的。首先它是一个 32 位的长度,主要存放我们的 Java 的八大基础数据类型,一般 32位就可以存放下,如果是 64 位的就使用高低位占用两个也可以存放下,如果是局部的一些对象,比如我们的 Object 对象,我们只需要存放它的一个引用地址即可。(基本数据类型、对象引用、returnAddress 类型)
- 操作数栈
存放我们方法执行的操作数的,它就是一个栈,先进后出的栈结构,操作数栈,就是用来操作的,操作的的元素可以是任意的 Java 数据类型,所以我们知道一个方法刚刚开始的时候,这个方法的操作数栈就是空的,操作数栈运行方法是会一直运行入栈/出栈的操作
- 动态连接
Java 语言特性多态(需要类加载、运行时才能确定具体的方法,后续有详细的讲解)
- 返回地址
正常返回(调用程序计数器中的地址作为返回)三步曲
- 恢复上层方法的局部变量表和操作数栈
- 把返回值(如果有的话)压入调用者栈帧的操作数栈中
- 调整
PC计数器的值以指向方法调用指令后面的一条指令
异常的话(通过异常处理器表(非栈帧中的)来确定)
# (3) 本地方法栈
本地方法栈保存的是 native 方法的信息,例如 Object 的 hashCode() 方法,当一个 JVM 创建的线程调用 native 方法后,JVM 不再为其在虚拟机栈中创建栈帧,JVM 只是简单地动态链接并直接调用 native 方法
执行本地方法。各虚拟机自己实现,本地方法栈 native 方法调用 JNI 到了底层的 C/C++(C/C++ 可以触发汇编语言,然后驱动硬件)
# 2、线程共享的区域
# (1) 方法区
存储的内容:类信息、常量、静态常量、即时编译期编译后的代码。
用于存储已经被虚拟机加载的类信息,常量("zdy","123"等),静态变量(static 变量)等数据,可用以下参数调整:
JDK1.7 及以前叫永久代,JDK1.8 及以后叫元空间。
jdk1.7 及以前:-XX:PermSize;-XX:MaxPermSize
jdk1.8 以后:-XX:MetaspaceSize; -XX:MaxMetaspaceSize
jdk1.8 以后大小就只受本机总内存的限制
如:-XX:MaxMetaspaceSize=3M
# (2) Java堆
几乎所有对象都分配在这里,也是垃圾回收发生的主要区域,可用以下参数调整:
-Xms:堆的最小值;
-Xmx:堆的最大值;
-Xmn:新生代的大小;
-XX:NewSize;新生代最小值;
-XX:MaxNewSize:新生代最大值;
例如运行时设置堆的最大值为256m的参数: -Xmx256m
# 六、JVM各版本内存区域的变化
运行时常量池是指: Class 文件中的常量池(编译器生成的各种字面量和符号引用)在类加载后被放入的区域
字面量:String a = "我是字面量" 中的 "我是字面量" 就是字面量。
- jdk1.6
运行时常量池在方法区中
- jdk1.7
运行时常量池在堆中
- jdk1.8
去永久代:原来的永久代占用的内存可能还会与堆有相互的关系,但是使用元空间后大小只受制于机器的内存,为什么这么做呢?永久代来存储类信息、常量、静态变量等数据不是个好主意, 很容易遇到内存溢出的问题。
对永久代进行调优是很困难的,同时将元空间与堆的垃圾回收进行了隔离,避免永久代引发的 Full GC 和 OOM 等问题;
# 七,直接内存
不是虚拟机运行时数据区的一部分,也不是 Java 虚拟机规范中定义的内存区域,它是 JVM 无法直接管理的内存。
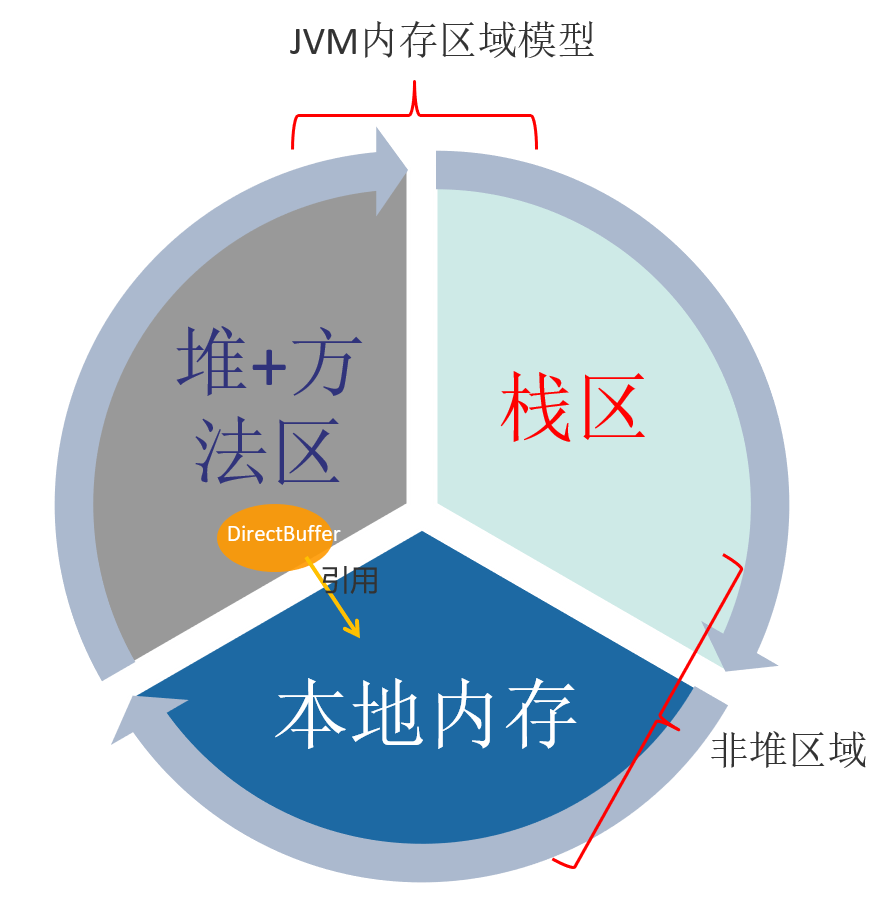
如果使用了 NIO,这块区域会被频繁使用,在 Java 堆内可以用 directByteBuffer 对象直接引用并操作;
这块内存不受 Java 堆大小限制,但受本机总内存的限制,可以通过 MaxDirectMemorySize 来设置(默认与堆内存最大值一样),所以也会出现 OOM 异常;
避免了在 Java 堆和 Native 堆中来回复制数据,能够提高效率